通常当服务端工程师谈论 CPU 核心的时候,更多地时候在乎的是数量而不是质量,比如我们开发了一个 Java 服务的容器需要申请一个 4 核 32 GB 内存的套餐(4C32G),还开发了一个 Golang 服务需要 4C8G 的 quota(我真的不是在黑 Java),但我们绝大多数时候并不会关心底层的 4 个核心来自于 AMD 还是 Intel 品牌的 CPU, 更别说具体什么 Xeon 还是 EPYC 型号了。
因为大部分服务端的问题都可以水平扩容来得到解决,四颗核心不够了,那我们申请六颗核心就好了,如果不能通过水平扩容解决问题,那就让服务架构变成可以通过水平扩容解决问题。
但总有一些问题是必须直面硬件本质的,比如高频交易场景(High-Frequency Trading,HFT),行情到来的瞬间,竞争对手只需要比你快一纳秒将订单提交给交易所前置,就能轻松夺走你苦苦挖掘的机会,Profit or Loss?单颗核心的性能才是真正的决胜关键。
每次行情到来的瞬间都是一轮残酷的竞赛游戏的开始,为了赢下这场比赛,如何能极致地压榨一颗 CPU 核心,将至关重要。

基准测试
不量化的优化是盲目的冒进
在工程领域,当我们要进行性能优化时,首先要从基准测试开始,没有测量,就没有办法知道优化的效果。
对于 CPU 的性能测试是一个很普遍的需求——单核跑分,有非常多现成的工具可以选择,比如 stress-ng 、 sysbench 等:
taskset -c 3 sysbench cpu --threads=1 --cpu-max-prime=20000 run
本质上,我们就是需要知道单位时间内,CPU 可以执行多少条指令。
或者我们也可以选择自己编写一个简单的基准测试程序,来测量 CPU 的性能,比如就是单纯的测量每秒钟能进行的浮点数运算:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, char *argv[]) {
// 检查命令行参数
if (argc < 2) {
printf("Usage: %s <iterations>\n", argv[0]);
return 1;
}
// 将参数转换为无符号长长整数(循环总数)
unsigned long long iterations = strtoull(argv[1], NULL, 10);
// 使用 volatile 防止编译器优化掉 dummy 运算
volatile double dummy = 0.0;
// 获取开始时间
struct timespec start, end;
if (clock_gettime(CLOCK_MONOTONIC, &start) != 0) {
perror("clock_gettime start");
return 1;
}
// 执行指定次数的循环,dummy 用于简单的运算
for (unsigned long long i = 0; i < iterations; i++) {
dummy += 1.0 / (i + 1);
}
// 获取结束时间
if (clock_gettime(CLOCK_MONOTONIC, &end) != 0) {
perror("clock_gettime end");
return 1;
}
// 计算总耗时(秒)
double elapsed = (end.tv_sec - start.tv_sec) +
(end.tv_nsec - start.tv_nsec) / 1e9;
// 计算每秒平均循环次数 (防止除 0)
double iterations_per_second = (elapsed > 0) ? iterations / elapsed : 0;
// 输出测试结果
printf("循环次数: %llu\n", iterations);
printf("耗时: %.6f 秒\n", elapsed);
printf("平均每秒循环次数: %.0f\n", iterations_per_second);
printf("Dummy值: %f\n", dummy); // 防止优化掉 dummy 运算
return 0;
}
硬件层面
换 CPU
就像在一个公司里,资金允许的情况下,与其费劲心思压榨引导监督员工干活解决某一个问题,不如直接雇佣一名这方面的专家能够更好地解决问题。
以世面上目前比较主流的服务器 CPU 型号 Intel® Xeon® Platinum 8592+ 为例,基础频率 1.9 GHz,最大睿频也就 3.9 GHz,但服务器 CPU 更多地考虑吞吐量和稳定性,所以不会极致地追求单核性能。
我们可以一步到位直接选择当下地表最强单核商业 CPU —— Intel® Core™ i9 14900KS,最大睿频 6.2 GHz,6.2 GHz 意味着每秒 62 亿次(6,000,000,000 次)!!!时钟周期,比 8592+ 快 60% 。

时钟周期和我们的代码又有什么关系呢?
回顾一下,我们的高级编程语言中的一行代码会可能编译出多条汇编指令,一条指令可以被简单拆解为五个阶段,每个时钟周期可以执行一个阶段。
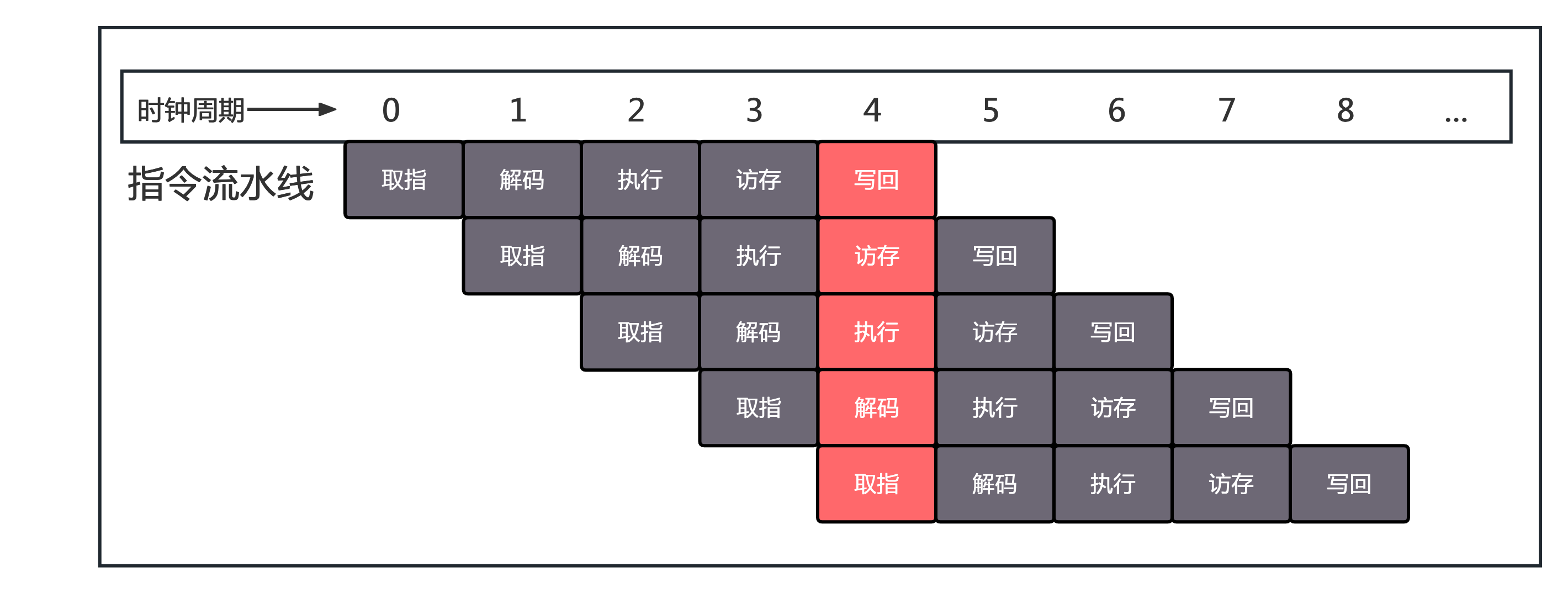
实际上,现代 CPU 的架构远不止这么简单,超标量、乱序执行、专用单元等优化技术可以使得每个周期完成不止一条指令。
以 Intel i9-14900KS 为例,基于 Raptor Lake 架构性能核心的 IPC(Instructions Per Cycle) 约为 3.5,意味着平均每个周期可以执行 3.5 条指令,单个核心每秒钟可以执行两百亿条指令!
以这个简单的计算函数为例,先进行加法然后进行乘法:
int calculate(int a, int b) {
int c = a + b;
int c = c * 2;
return c;
}
其对应的汇编代码大致如下,一共十二条指令:
calculate: # int calculate(int a, int b) {
# 函数序言
pushq %rbp # 保存前一个函数的基址指针
movq %rsp, %rbp # 设置新的基址指针
# 保存参数
movl %edi, -20(%rbp) # 保存参数a (来自edi寄存器)
movl %esi, -24(%rbp) # 保存参数b (来自esi寄存器)
# int c = a + b;
movl -20(%rbp), %edx # 加载a到edx
movl -24(%rbp), %eax # 加载b到eax
addl %edx, %eax # 执行a + b,结果在eax
movl %eax, -4(%rbp) # 保存结果到c (栈上位置为rbp-4)
# c = c * 2;
sall -4(%rbp) # 对c做左移1位操作 (等价于c * 2)
# return c;
movl -4(%rbp), %eax # 加载c到eax寄存器作为返回值
# 函数尾声
popq %rbp # 恢复之前保存的基址指针
ret # 返回到调用函数
按 8592+和 14900KS IPC 均为 3.5 考虑,最大睿频的情况下:
8592+每秒可以执行 3.5 * 3.9 * 10^9 = 13.65 * 10 ^ 9 条指令, 每秒指令需要 1*10^9 / 13.65 * 10^9 = 0.07326007ns14900KS每秒可以执行 3.5 * 6.2 * 10^9 = 21.7 * 10 ^ 9 条指令, 每秒指令需要 1*10^9 / 21.7 * 10^9 = 0.04608295ns
执行十二条指令的话,两者分别需要 0.87ns 0.55ns,我们真实软件开发程序中的函数会远比这复杂,看似简单的调用几个库函数,被和可能就是成千上万条指令,这个差距会等比例放大到 87us vs 55us -> 87ms vs 55ms直到能被上层业务逻辑非常明显的感知到。
(当然这是一个非常理想的计算模型,实际上编译器和处理器会有各种各样子的黑魔法优化,指令并不一定能并行,不同指令的执行长短也不一样,甚至哪一天这个函数也被打包成了一条专用的指令也说不定,毕竟 CISC 多一条指令也不多 :) )
超频
首先不管具体使用哪一个型号的 CPU,超频都是非常必要的。
CPU 运行频率是由CPU时钟决定的,由主板晶振 + 倍增器实现的,不过我们可以把时钟简单理解为一个不断震荡输出高低电平的电子元件,震荡一次,庞大的 CPU 门电路系统就会运行一次,完成一次宏观意义上的计算。

主板晶振频率通常是 100MHz,我们只需要修改倍增系数就能实现超频,比如想要超到 9.0GHz,就将倍增系数调整到 90 即可。
超频最大的问题来自于电压和散热:
- 电压过低 -> 晶体管无法跟上切换节奏 -> 计算错误 -> 蓝屏
- 散热不足 -> 温度过高 -> 触发温度保护 -> 死机
目前最极限 CPU 运行频率的世界记录是 9.12GHz,是不是想象空间非常大?当然这是在非常极端的情况下,Wytiwx 使用了一颗 i9-14900KF,搭配 2 * 1600W 大功率电源,使用液氦将CPU冷却到零下 200 度来实现的。这种时钟频率下系统可能只能稳定运行几秒钟, 就只够跑个分截个图的时间。
如果想要解决一些实际的问题,我们会需要一套更加稳定的超频方案,每颗 CPU 的体质不一样,这可能是一个需要不断尝试的组合结果。
另外主板上面还有一些其他的 CPU 相关的配置可以调节,有助于避免 CPU降频:
- 关闭
Efficient核心,关闭一些用不到的小核心 - 关闭
C-State,避免CPU进入省电模式 - 禁用
AVX指令集,如果用不到的话,可以禁用以减少功耗
禁用超线程
超线程(Hyper-Threading)技术是 Intel 开发的一项技术,可以让一个物理核心模拟出两个逻辑核心,让操作系统认为有两个核心可以调度,从而提高 CPU 的并行处理能力。
但在我们的场景下,超线程反而会带来负面影响: - 两个逻辑核心会共享物理核心的资源(如缓存、执行单元等) - 当两个线程同时运行时,会互相争抢资源,导致性能下降 - 缓存失效和上下文切换的开销会更大
我们可以通过以下方式禁用超线程:
- 在 BIOS 中直接禁用
- or 通过内核启动参数 noht 禁用
- 或者通过 echo 0 > /sys/devices/system/cpu/smt/control 动态禁用
操作系统层面
当我们在硬件层面将 CPU 压榨到了极致之后,例如 6.0GHz 每秒六十亿次计算,接下来我们的问题就是如何让这一个核心在一秒钟六十亿个时钟周期都在执行我们期望的指令。
这并不是一件理所当然的事情,我们无法直接使用裸的 CPU 硬件资源,需要委托操作系统这一层硬件的抽象来执行。
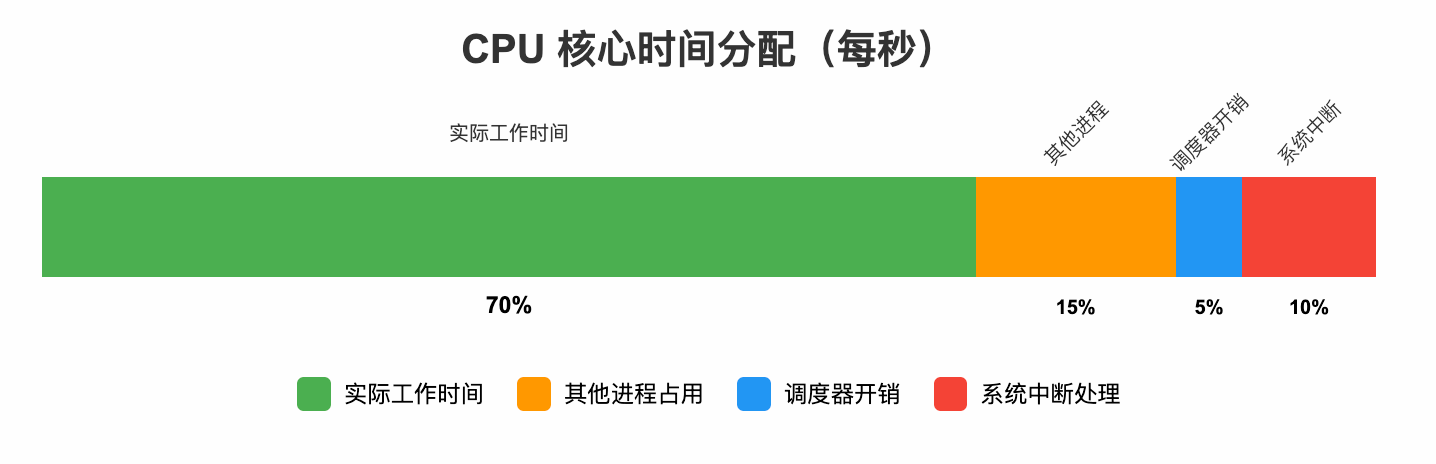
现代操作系统的设计理念通常是多任务兼顾效率与公平,然而我们要的就是特权、要是就是独占;另外操作系统本身也会有一些“元任务”会占用我们的 CPU 核心。
理论上较差的情况下,我们辛辛苦苦压榨出来的 CPU核心甚至我们自己只能从操作系统手中分得70%的时间片,这是非常难以接受的。
核心隔离 & 绑核
默认情况下,所有的 CPU 核心都会参与操作系统的调度,当我们的程序运行的时候,很有可能会有不长眼的其他线程抢占我们的 CPU 核心,然后我们的程序被迫暂停,等待下一次调度,即使这个线程执行时间很短迅速的归还了核心的使用权,然后上下文的切换以及对应核心 CPU 缓存的失效等都会带来巨大的开销。
最好这颗核心能自始至终只为我们的程序那一个线程服务。
我们可以根据需要,将一定数量的 CPU 核心隔离出来,将它们排除在操作系统调度之外,我们的线程再通过特殊的手段将它们绑定到这些核心上,这样我们的程序就可以独占这些核心。
在内核启动参数中添加 isolcpus=N 参数就可以实现核心隔离,然后通过 taskset 或者 sched_setaffinity 系统调用就可以将线程绑定到这些核心上。
减少中断
中断(Interrupt)是为了避免轮询而设计出来的一种机制,它可以让 CPU 在正常情况下专注当前任务,只在需要的时候才暂停当前任务,然后去处理中断。
举个例子,以服务器上最常见的中断类型——网卡中断为例:
1. 网卡设备收到数据后,会通过 DMA 控制器将数据写入内存
2. 然后网卡会向 CPU 发送一个中断,告诉 CPU 可以去处理数据了
3. 这个时候 CPU 会暂停当前任务,保存当前上下文
4. 然后 CPU 会切换到内核态开始执行内核代码处理这些数据
5. 从 DMA buffer 读取网络包转换成 sk_buff 然后唤醒等待在 sk_buff 队列上的线程
6. 在用户态看来就是 recvfrom 系统调用返回数据了
7. 干完这一堆事情,CPU 才能再继续重新加载上下文,继续执行之前的任务。
这种机制在大多数场景下是非常合理的,但对于我们这种追求极致性能的场景来说,中断带来的上下文切换开销是不可接受的:
- 中断处理程序会打断当前任务的执行,导致 CPU 流水线被清空
- 中断处理程序会使用 CPU 缓存,导致当前任务的缓存被污染
- 中断处理完成后,还需要恢复之前的上下文,这个过程也会带来开销
我们需要尽可能的让我们的核心,远离这些中断。
IO 中断
首先针对 IO 类中断而言,我们可以配置亲和性让它们只在特定的核心上运行:
- 配置内核参数: irqaffinity=0,8-11
- 或者手动为所有的中断设置亲和性:echo $MASK > /proc/irq/$i/smp_affinity
另外 irqbalance 工具可能会覆盖亲和性配置,可以直接禁用这个服务 systemctl disable irqbalance。
时钟中断
时钟中断是一种比较特殊的中断,它会周期性在每一颗 CPU 核心上触发,操作系统会定期检查是否需要进行线程切换,默认情况下会根据配置的时钟频率 HZ来触发。
Linux 提供一项 Dynamic Ticks 特性,可以在 CPU 上只存在一个线程运行的情况下大幅减少时钟中断的触发次数,因为也没有必要太多的检查。
我们可以通过修改内核参数来为我们的核心启用这项特性:
- nohz=on # 启用 Dynamic Ticks 功能
- nohz_full=1-7 # 在特定 CPU 核心上启用 Dynamic Ticks
- skew_tick=1 # 避免多个核心同时触发时钟中断带来的性能抖动
- rcu_nocbs=1-7 # 不处理 RCU 回调
禁用死锁检测
死锁检测(Deadlock Detection)是 Linux 为了避免系统陷入死锁而设计的一种机制,它会定期检查系统中的进程是否存在死锁的可能;这种检测会由时钟中断触发,在每个 CPU 核心上都消耗一定的资源
我们可能通过添加内核参数 nowatchdog nosoftlockup 进行禁用。
写在最后
最后写点题外话,本来在纠结写出来会不会显得有点刻意升华,毕竟这是一篇技术文章,但仔细思考后,觉得这个类比确实很有启发,所以还是决定写下来。
其实我们的人类的 CPU —— 大脑,和计算机的 CPU 也很像,当我们想要极致的“压榨”我们的大脑时,其实也是这两个方向:
- 持续学习,锻炼思维能力、积累思维框架与方法论,提升单位时间内大脑的 token 输入输出处理能力
- 专注于主线任务,减少上下文切换,将大脑的时间片留给关键任务;当我们需要深度思考时,也应该为大脑创造一个「隔离」的环境,远离各种「中断」
极致的优化,不只是技术的追求,更是对自我认知和成长的探索。