WHY 共享内存
进程间通信有许多种方式,不同的场景有不同的选择。
当通信内容非常简单的时候,可以考虑信号、信号量甚至 flock() 这种最基础的通信方式。
当需要传递不仅仅是信号这种规模的数据时,可以考虑 FIFO、MQ 等内核 API,也非常的简单易用 。
当我们的传输内容再进一步复杂,需要用“协议”去抽象这种复杂度的时候,Unix Domain Socket 会是一个不错的选择,比如常见的 gRPC over UDS;或者牺牲一点网络栈开销,直接使用基于 TCP / UDP 的 Socket 也非常方便。
十八般兵器各有神通,但本文主角——共享内存,光凭零数据拷贝这一特性就能稳坐最快进程间通信方式这一宝座。
其实线程间的通信方式本质上也是共享内存,只不过线程之间的内存天然就是“共享“的,而进程之间的通信相对而言则要复杂许多。

内存
在深入了解共享内存之前我们先来简单回顾一下内存,每一个程序在运行时有大量的数据需要存放,磁盘太慢而寄存器太小,所以绝大部分运行时数据都会被存储在以电容电荷数量或者锁存器锁止电压高低为基本单元的易失性半导体存储器中,也就是我们所熟知的内存条。
内存本质上就是一个大数组一字排开,比如 16 GB 的内存条,那么就可以视为一个长度为 2^30 的数组,每个单元中盛放着一个字节。
现代操作系统出于降低程序复杂度、安全性、隔离性等角度的考虑,通常会在物理内存的基础上引入一层虚拟内存的抽象,然后由 MMU 查询操作系统提供的页表再翻译成物理内存地址。
以 64 位 Linux 操作系统为例,理论上虚拟内存的地址空间大小是 2^64 字节为 16EB,带有一个非常巨大的单位,很显然当前的计算机是远远用不到这么大的空间的,Linux 将高 16 位暂时封存了,剩下的 128TB 低地址空间留给用户空间使用,128TB 高地址空间则对应的留给内核空间。
用户空间内存段的详细划分可以参考下图,这里我们主要关注其中一个特殊的区域:内存映射区。
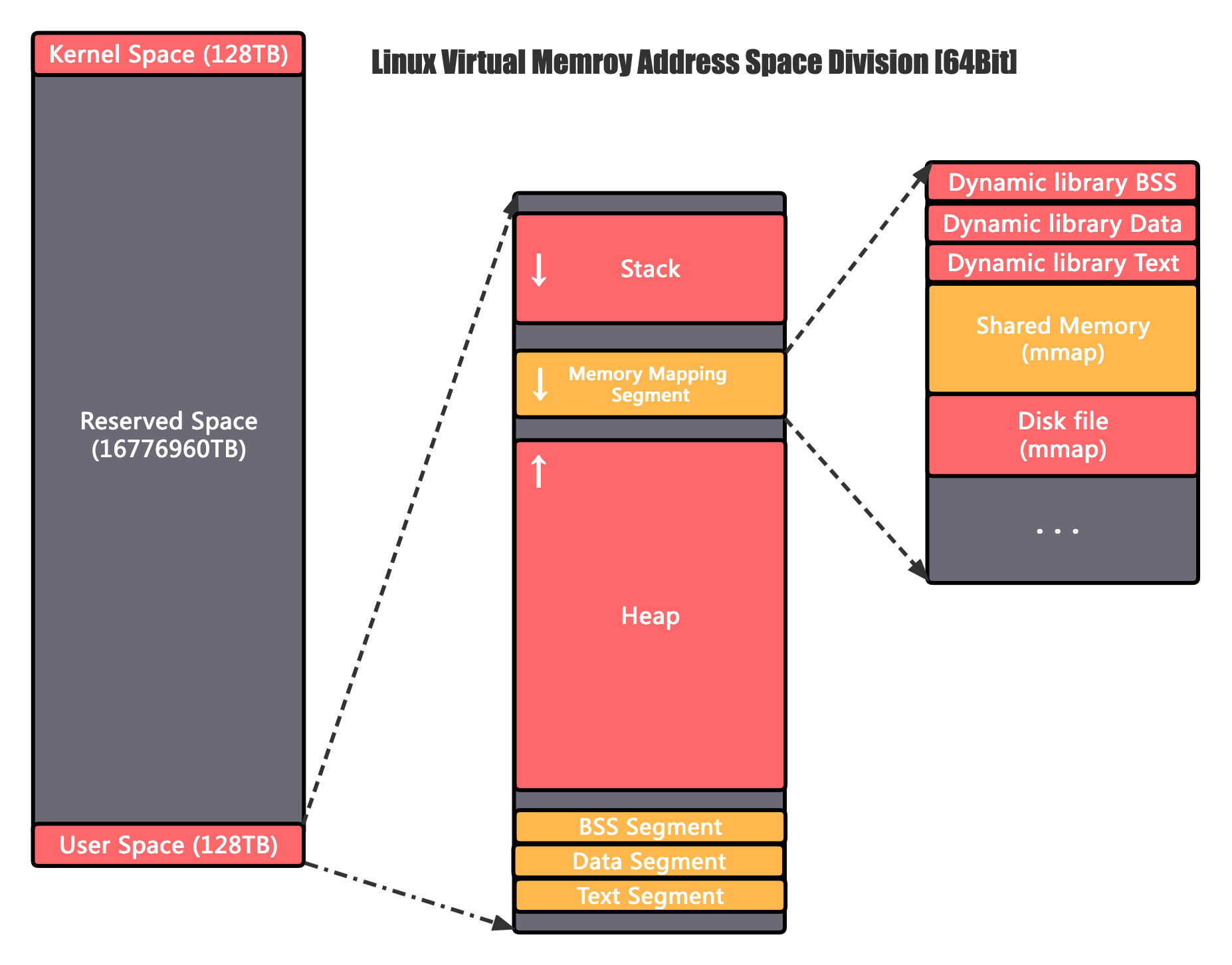
内存映射区顾名思义就是从进程外部映射进来的内存,类似于一个超链接,常见的内存映射有三种:
- 动态链接库的代码段、常量、静态变量,由于是动态的,而当前进程的对应空间是在编译时就已经确定好了的,所以不可能放到一起,另外出于节约资源的角度考虑,共享内存的只读部分只会占用一份内存,然后其他要用到这些库的程序只需要链接过去即可复用,因此动态链接库对应数据的地址也会被放置在内存映射区
- 磁盘文件映射,当对磁盘文件读写性能要求很高时,部分应用会使用 mmap 将文件内存直接映射到内存空间,省去数据从内核态拷贝到用户态的开销
- 还有就是本文的主角——共享内存,实际的内存也只会打开一份,然后分别被映射到不同进程的地址空间中
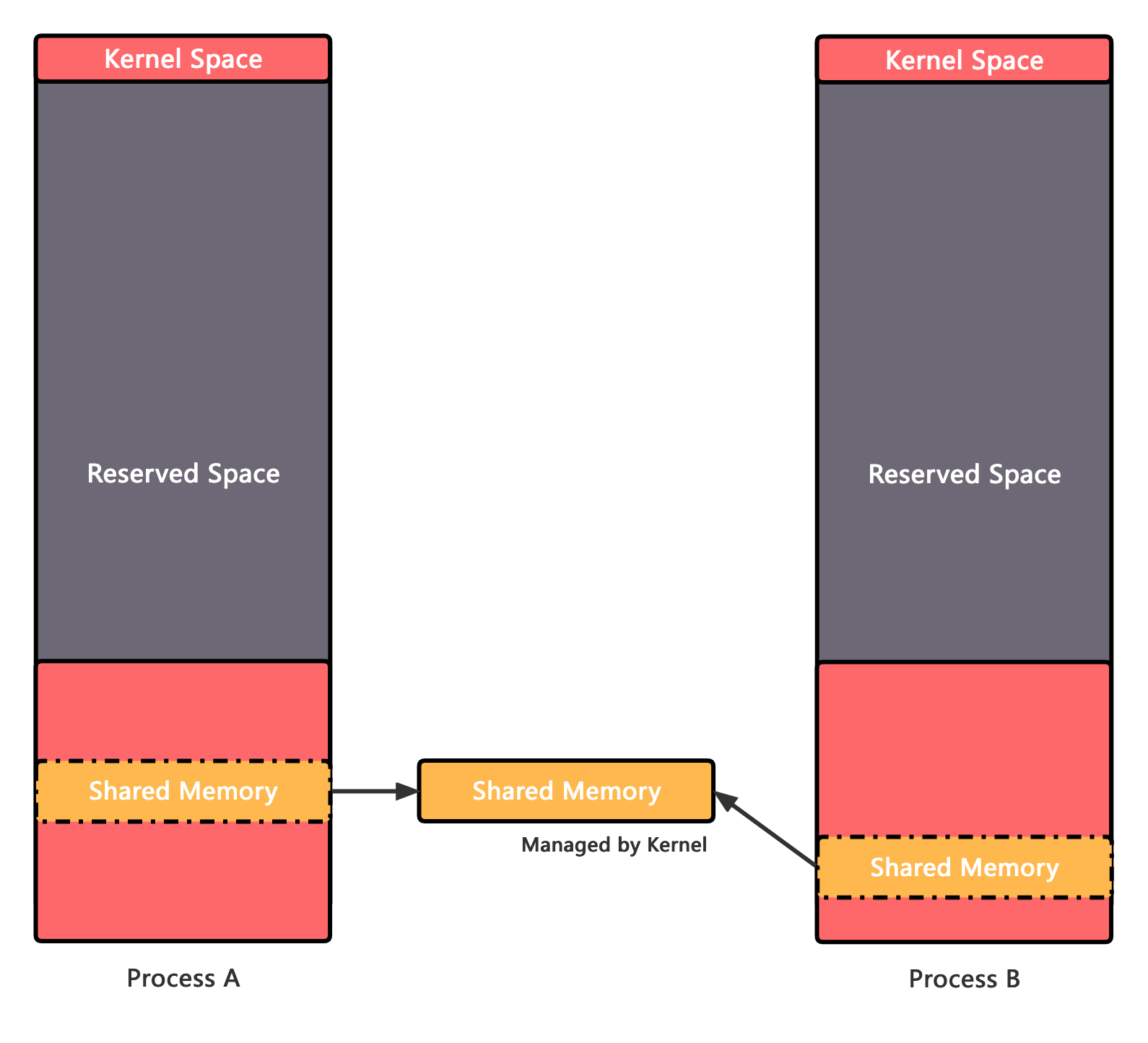
接入方式
Linux 系统上,共享内存目前有两套 API 可以接入使用,POSIX 和 System V。
POSIX
1993 年在 IEEE 1003.1B 标准中定义了一系列”实时计算“相关的 API,如 I/O、IPC、多线程等相关内容,其中就包括共享内存的相关 API 定义。
由于是 POSIX 标准,所以支持 POSIX 的操作系统目前都能使用这一套 API,跨平台性相较于 System V 而言更好,另外代码实现相对更加简洁,排查分析问题也比较方便。
下方实现基于 glibc v2.37 版本分析
API
POSIX 共享内存由如下几个相关函数组成:
// 打开一个代表共享内存的临时文件,返回其对应的 fd
int shm_open(const char *name, int oflag, mode_t mode);
// 分配空间
int ftruncate(int fd, off_t length);
// 关闭共享内存
int shm_unlink(const char *name);
实现原理
POSIX 的大部分标准在 glibc 中都有实现,共享内存也是如此,其实现非常简洁。
tmpfs 是一种特殊的文件系统,与磁盘文件系统不同,tmpfs的数据存储在内存中,Linux 在启动之后会挂载多个 tmpfs实例,各自有其不同的用途,其中之一 /dev/shm就是为共享内存提供服务的。
既然已经提到内存文件系统了,那么我们很自然的就能想到,只需要在内存文件系统上创建一个文件,然后几个进程同时对该文件进行操作,不就是在共享内存么?
是的,在 glibc 的实现版本中,其实现就是这么简单,shm_open.c 和 shem_unlink.c 总共不到一百行代码,就实现了这套共享内存的 API。
值得注意的是,shm_open 和open其实没有本质上的区别,只是会限制该文件必须是位于 /dev/shm下面的临时文件,它与普通的文件 open 一样,返回一个文件描述符,随后的 ftrucate() write() read() mmap()等操作其实就都是通用的 I/O API 了。
一般来说,我们通常会通过 mmap将这个”文件“映射到进程的虚拟地址中,方便我们后续以内存的形式来使用这个”文件“,当然,我们也是可以继续用 read() write() 进行数据读写的。
DEMO
直接阅读代码能更清晰直观的了解共享内存的使用方式,以下是共享内存写入和读取部分的代码示例 :
写入部分:
writer.c#include <sys/mman.h> #include <sys/stat.h> /* For mode constants */ #include <fcntl.h> /* For O_* constants */ #include <unistd.h> #include <string.h> #define PATH "/testing-shared-memory" #define SIZE 1024 int main() { int fd = shm_open(PATH, O_CREAT | O_RDWR, 0600); if (fd == -1) return -1; // 申请空间 if (ftruncate(fd, SIZE) == -1) return -1; // 内存映射 char *shm = (char *) mmap(NULL, SIZE, PROT_WRITE, MAP_SHARED, fd, 0); if (shm == MAP_FAILED) return -1; // 共享内存写入 strcpy(shm, "HELLO WORLD"); // 回收资源,这里其实 mmap 之后 fd 就用不到可以 close 了 close(fd); munmap(shm, SIZE); }读取部分:
reader.c#include <sys/mman.h> #include <sys/stat.h> /* For mode constants */ #include <fcntl.h> /* For O_* constants */ #include <unistd.h> #include <string.h> #include <stdio.h> #define PATH "/testing-shared-memory" #define SIZE 1024 int main() { int fd = shm_open(PATH, O_RDONLY, 0600); if (fd == -1) return -1; // 内存映射 char *shm = (char *) mmap(NULL, SIZE, PROT_READ, MAP_SHARED, fd, 0); if (shm == MAP_FAILED) return -1; // 读取内存内容 printf("%s", shm); // 回收资源 close(fd); munmap(shm, SIZE); // 删除这段空间 shm_unlink(PATH); }
保存好 writer.c和reader.c之后,我们编译并运行就可以看到 reader 能成功读出来 writer 写入的数据了:
# 编译, rt 是 shm_open 所在的库
gcc -o writer -lrt writer.c
gcc -o reader -lrt reader.c
# 运行
./writer
./reader
> HELLO WORLD
System V
System V 是上个世纪流行的一种 Unix 操作系统,虽然目前我们已经不再经常遇见这个操作系统,但是它的一些遗产仍然被 Linux 所继承,比如 /etc/init.d 以及其进程通信机制。
尽管 POSIX 系列标准吸取了前人的经验,设计出更统一、现代、灵活的 POSIX IPC 系列标准,但是在一些遗留系统或特定需求下,System V IPC 仍然可能有其用武之地。
System V IPC 由三部分组成:消息队列、信号量和共享内存,消息队列允许进程通过在队列中传递消息来进行通信,信号量可用于控制对共享资源的访问,而共享内存则允许多个进程共享同一块内存区域,从而实现更快速的数据交换。
API
// 申请一块共享内存
int shmget(key_t key, size_t size, int shmflg);
// 将创建好的共享内存地址附加到当前进程的内存地址空间(其实就是 mmap)
// shmaddr 是目标地址可以不用指定,由内核分配
void *shmat(int shmid, const void *_Nullable shmaddr, int shmflg);
// 取消内存映射
int shmdt(const void *shmaddr);
// 控制共享内存,可以传入不同的 cmd 查询或者删除 shmid 所对应的共享内存
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
实现原理
System V 共享内存的代码实现在Linux 内核内部,其实现原理和 glibc 实现的共享内存类似,它同样是通过内存文件系统打开一个文件,然后将其映射到内存中,从而实现进程间的共享数据,这里就不详细展开了。
一段 System V 共享内存在 Linux 里被叫做Segment,每段共享内存在内核里面对应一个 shmid_kernel的数据结构:
struct shmid_kernel {
struct kern_ipc_perm shm_perm; //
struct file *shm_file; // 对应的内存临时文件
unsigned long shm_nattch; // Attach 的内存数量
unsigned long shm_segsz; // 共享内存大小(Bytes)
time64_t shm_atim; // 最后一次访问时间
time64_t shm_dtim; // 最后一次连接断开时间
time64_t shm_ctim; // 创建时间
struct pid *shm_cprid; // 控制进程的 PID (通常就是创建者,但是创建者可能会退出)
struct pid *shm_lprid; // 也是指向控制进程的 PID
struct user_struct *mlock_user;
struct task_struct *shm_creator; // 指向创建进程的 task_struct
struct list_head shm_clist; // 被同一进程创建的共享内存会通过这个链表串联
}
我们可以通过 ipcs -m 命令来查看这个结构体的关键信息。
在 Linux 中,默认情况下,每个共享内存段(Segment)的最小长度为 1KB。而最大长度可以达到 2^64 - 2^24,这几乎相当于没有限制。
此外,默认情况下,系统允许创建的最大共享内存段数量是 4096。如果需要创建更多的共享内存段,就需要使用 sysctl 命令进行调整。
DEMO
System V 的 API demo 也是分为两部分,写入共享内存和读取共享内存,如下:
写入部分
writer.c:#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/ipc.h> #include <sys/shm.h> #define SHM_SIZE 1024 // 共享内存大小,以字节为单位 int main() { key_t key = ftok("testing-shared-memory", 1); // 创建一个唯一的键 // 创建共享内存段 int id = shmget(key, SHM_SIZE, IPC_CREAT | 0666); if (id == -1) return -1; // 附加共享内存 char *shm = (char *) shmat(id, NULL, 0); if (shm == (char *) -1) return -1; // 共享内存写入 strcpy(shm, "HELLO WORLD"); // 分离共享内存 shmdt(shm); return 0; }读取部分
reader.c#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/ipc.h> #include <sys/shm.h> #define SHM_SIZE 1024 // 共享内存大小,以字节为单位 int main() { key_t key = ftok("testing-shared-memory", 1); // 使用同样的键 // 获取共享内存段 int id = shmget(key, SHM_SIZE, 0666); if (id == -1) return -1; // 附加共享内存 char *shm = (char *) shmat(id, NULL, 0); if (shm == (char *) -1) return -1; // 读取共享内存中的数据 printf("%s", shm); // 分离共享内存 shmdt(shm); // 删除共享内存段(可选) shmctl(id, IPC_RMID, NULL); return 0; }
实际应用
理论上进程间通过共享内存通信的性能是能做到和进程内部线程间通信性能一致,因此共享内存在高性能计算、大批量处理、实时分析系统等场景均有广泛的应用。
但当我们实际要基于共享内存开发应用的时候,原来编程语言提供的进程内各种同步原语、锁等API 全部都无法使用了,处理进程间同步的问题会是一件比较棘手的事情,另外由于不同进程内分配到的虚拟内存的地址并不一样,因此部分语言的容器、散列表等数据结构可能也无法使用,此时考虑基于一些优秀的第三方开源库去实现基于共享内存的通信可能是一个不错的选择:
SPSC_Queue: 基于 C++ 实现的 RingBuffer 的无锁队列,可以说几乎是单生产者单消费者模型下的最快通信方式了,简单且暴力
zmq_ipc: ZeroMQ 是一个款多用途的消息队列,zmq_ipc 只是其提供的其中一种传输方式,但也有着非常广泛的使用
Boost.Interprocess Boost (C++ 库)的一个模块,提供了一些进程间通信的辅助 API,其中就包括支持共享内存的 STL、进程间锁、内存分配器等非常实用的功能
iceoryx:功能很强大的 C++ 进程通信框架,支持请求响应、消息、回调、注册发现等通信模型,另外很难能可贵的是,目前主流的操作系统几乎全部都支持
shmipc-go: 基于 Golang 的进程间通信框架,使用 TCP over UDS 进行进程间同步空间,共享内存传递数据,支持”批量收割” IO 优化性能
libshmcache: 多进程共享缓存,号称在单机环境下比 Redis 快一百倍,支持 Java、C 和 PHP 接口
tcpshm: 这个项目可以让我们在共享内存之上运行 TCP 协议,强一致性协议,每一个包都会有 ACK 回调
参考文档
[1] shm_open.c: https://elixir.bootlin.com/glibc/latest/source/rt/shm_open.c
[2] shem_unlink.c: https://elixir.bootlin.com/glibc/glibc-2.37/source/rt/shm_unlink.c
[3] Linux 内核内部: https://elixir.bootlin.com/linux/v6.4/source/ipc/shm.c
[4] SPSC_Queue: https://github.com/MengRao/SPSC_Queue
[5] zmq_ipc: https://github.com/zeromq/libzmq/blob/master/doc/zmq_ipc.txt
[6] Boost.Interprocess: https://github.com/boostorg/interprocess
[7] iceoryx: https://github.com/eclipse-iceoryx/iceoryx
[8] shmipc-go: https://github.com/cloudwego/shmipc-go
[9] libshmcache: https://github.com/happyfish100/libshmcache
[10] tcpshm: https://github.com/MengRao/tcpshm
[11] IEEE 1003.1b Standard: https://standards.ieee.org/ieee/1003.1b/1392/
[13] shm_open() API: https://man7.org/linux/man-pages/man3/shm_open.3.html
[14] System V IPC: https://man7.org/linux/man-pages/man7/sysvipc.7.html