Redis 官网 FAQ 翻译以及部分自己生产实践总结的问题 官网FAQ地址
Redos持久化策略:RDB和AOF
RDB:数据快照,数据整体快照,吞吐量较大,但单次耗时较长,如果在dump的时候宕机可能会导致数据丢失。 AOF:日志追加,占空间比RDB大,但安全性更好,每秒追加一次日志,丢失数据的可能性会小很多,但是宕机恢复很慢。
而在实际生产环境中,我们通常会将两种持久化策略共同使用,定期进行数据快照,同时保留 AOF 日志,在快照之前的日志就可以删除了,这样既节省了空间,同时又能加快恢复速度,还能保证解决的数据持久可靠性。
Redis和其他的KV数据库有什么不同
- Redis支持额外的数据结构
- Redis是纯基于内存的
Redis内存占用情况怎么样
空的Redis —— 3MB 一百万小KV数据 —— 85MB
Redis以后打算出基于磁盘的版本吗,我想创建一个比内存更大的数据集
不会,我们始终专注内存,不忘初心,我们的口号是:“data served from memory, disk used for storage. ”;如果你觉得内存不够的话可以考虑下Redis集群;另外有些组织的魔改版本好像支持磁盘存储,但我们官方不会支持。
想要用支持磁盘的 KV 数据库的话,可以考虑 Level DB 和 Rocks DB。
Redis和基于磁盘的数据库一起用怎么样
很Nice,大家一般都是这么用的:大量频繁的小数据写入Redis,大对象写SQL入DB;还有一种用法就是,从DB中复制出来保存Copy在内存中
如何降低Redis的内存占用?
- 使用32位的Redis??
- 善用Redis数据结构,内部有优化,比独立的几个KV会更省空间
Redis用尽内存了会发生什么?
- Redis可能会被Linux kernel OOM kill 掉,报错崩溃或者是开始慢下来
- 你可以在配置文件中设置一个内存limit,当到达这个值后,Redis就会进入Read-only模式,拒绝写操作
- 在使用Redis作为LRU 缓存时可以设置达到limit移除一些key
Redis磁盘镜像备份是Atomic的吗?
是的,备份进程只会在server没有执行命令的时候执行
Redis是单线程的,为什么还能这么快,如何充分利用CPU?
- Redis的计算逻辑非常简单,是一个 IO 密集型服务。CPU并不是Redis的瓶颈,瓶颈往往来自于IO和内存,现在一个CPU已经很够用了,每秒可以处理一百万个请求,多线程反而会带来并发安全、线程切换等问题
- 但现在其实也有用到多线程,不过只干点小活,如:后台删除,拒绝命令等
- Redis 4.0开始官方也在尝试让Redis更加的多线程化,拭目以待吧
- 如果一个实例总是无法出分利用一台物理机的资源的话,可以部署多个实例将 Redis 集群化
Redis key上限是多少?Hash,List,Set成员上限是多少
2^32 ; 2^32
为什么我的从服务器key数量和主服务器key数量不一致?
因为Master在删除key时只是标记删除,会等后来的key来覆盖它,而在写入RDB时是不会把这些写过去的,但DBSZIE命令还会把它们算在里面,在逻辑上它的数量其实还是一样的
Redis名字的含义是什么?Redis为什么叫Redis?
REmote DIctionary Server:远程映射表服务
Redis分片的好处
- 增大Redis总内存
- 将Redis扩展到多
什么是Redis主从架构
Description : 将Redis服务器搭建成一主一从,或一主多从,主服务器负责写,从服务器负责读,读写分离提高性能,同时如果Master宕机,可以选举一位Slave成为新的Master,从而保证整个系统的稳定性,避免单点故障,甚至引起缓存击穿,缓存雪崩等问题
主从从架构:Slave slaveof Slave 形成一条链,缓解多个Slave同时同步于Master带来的压力
从库只读:可设置
Redis分区的实现方式
- 客户端分区,客户端判断好该去哪个机器上读取
- 代理分区:所有的请求都访问Proxy,然后Proxy给你返回结果,分片对Client不可见,Proxy内部帮你判断去哪台机器并完成请求 ;常见应用方式:Redis中间件,如:Twemproxy
- 路由分区:随机访问某个Redis,然后它帮你重定向到你该去的地方;Redis-Cluster
Redis Cluster
Redis Cluster是官方给出的集群实现 数据分片实现:哈希槽,CRC16对16384取模决定Key会被放置到哪个节点;后台维护一个值范围与节点的对应表,增加或减少节点时修改表中节点对应范围即可;使用路由分区算法 一致性:Master处理完写命令后异步复制到子节点上(为了及时响应),存在一个时间滞后,因此不能保证数据的强一致性;另外网络分区时也会导致写丢失 大致架构:路由分区+哈希槽+主从
Redis 为何要尽量避免大Key?
- 大Key会导致数据堆积在单一分片上,导致内存过大,响应变慢,不能充分利用集群的优势
- 由于单线程限制,单一Key在存取时会阻塞其他操作,导致Redis无法及时响应
Redis 一般多大的 Key 叫大 Key?
在我们团队的实践中,一般满足如下任一条件的 Key 会视为大 Key: 1. 普通 KV 类型 Value 大于 10KB 2. 集合类型 Key 中 元素个数大于5000 3. 集合类型 Key 整体 value 大于10MB(10*1000*1000)
具体也看对应的机器性能和业务类型,不同场景可以适当调整标准。
Redis实现分布式锁
SETNX key val 加锁:如果key存在,set key val return 1 ,else return 0 DELETE key 解锁:删除key expire:用于加锁时设置,超时自动释放锁,防止永久锁
什么是 O(n) 命令
我们知道 redis 正常查找一个 Key 的时间复杂度是 O(1) 的,而也存在一下命令时间复杂度和 Key 的数量是成正比的: hgetall、lrange、smembers、zrange、sinter、keys 等,这些命令对性能的影响是很大的,我们在生产环境中要尽量避开这些命令
Redis 有哪些数据结构
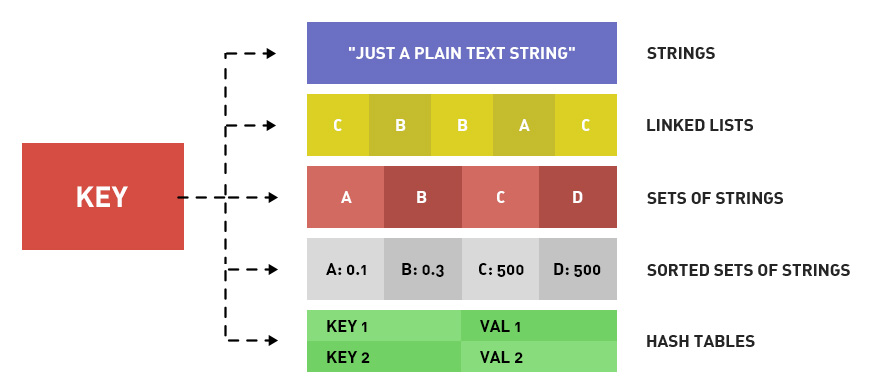
支持五种数据结构类型的值:
- 字符串
- 添加:set key value
- 带过期时间的添加:setex key seconds value
- 不存在才设置:setnx key value
- 自增:incr key
- 自减:decr key
- 追加:append key value
- 获取一个:get key
- 获取多个:mget key1 key2
- 删除:
- 链表: List
- POP: lpop table
- PUSH: lpush table key1 key2
- 获取第几个:lindex table index
- 集合: Set
- 添加:sadd table key
- 求交集:sinter table1 table2
- 求并集:sunion table1 table2
- 判断是否存在:sismember table key
- 全部取出:smembers table
- 定向删除:srem talbe key1 key2
- 随机删除:spop table key
- 有序集合: zset
- 添加:zdd table key score
- 遍历:正序:zrange table minIndex maxIndex 反序:zrevrange
- 删除:zrem table key
- 查看:zscore table key
- 哈希表:hash
- 增:hset table key
- 删:hdel table key
- 查:hget table key
- 遍历:hgetall table