Kernel
内核承担了核心的操作系统工作,是当今软件生态的基石,因此了解内核是如何工作的能极大的帮助我们更好地构建用户态系统。
学习软件源代码最好的方式就是边看边 DEBUG,软件 = 代码 + 数据,看代码的同时了解其运行时数据能让我们更好的理解整体逻辑。
但内核毕竟不是普通的软件系统,并不是简单的在 IDE 里面一点就能断点调试的,虽然也可以通过 kgdb + qemu 实现在 IDE 中的断点调式,不过这样实在是太重了,而且也不能分析正在运行中的线上系统,本文分享两种比较轻量级的内核调试小技巧,帮助我们快速地观测其运行时状态。
内核模块
我们通常写的代码都是运行在用户态下的,在 Linux 系统内,用户态程序运行时的指令会以 Ring 3 级别的权限运行,是无法访问到 Ring 0 级别的高地址位内存空间的,也就无法窥探内核里面的数据。
既然这样,想办法让我们的代码在内核运行不就好了。
直接修改内核代码,在里面加我们感兴趣的日志,编译安装运行肯定是可行的,可是改动起来难免有点繁琐。
宏内核的架构的 Linux 提供了一种热插拔的模块化扩展机制,我们可以开发一个内核模块,然后在里面读取我们感兴趣的变量,通过日志打印出来。
比如一个进程在 Linux 内核中的数据结构是 task_struct,我们可以轻松在内核源代码中找到其数据结构,可是这些字段具体在每个进程中的值又是怎样的呢?我们可以写一个内核模块一探究竟。
内核模块的接口非常简单,我们只需要实现初始化和清理两个函数即可,完整的开发教程可以参考文档:https://tldp.org/LDP/lkmpg/2.6/lkmpg.pdf。
我们先编写模块代码如下,保存到 kdebugger.c 文件中:
// 内核模块用不了标准库,需要引用内核专门的头文件
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sched/signal.h>
static int test_tasks_init(void) {
unsigned int process_count = 0;
struct task_struct *current_task;
// printk 的辅助函数,标准库 printf 的替代品
pr_info("%s: In init\n", __func__);
for (current_task = &init_task; (current_task = next_task(current_task)) != &init_task; ){
pr_info("\nCommand: %s PID: %d TGID: %d State: %ld Flags: %d Policy: %d Prio: %d StaticPrio: %d Current CPU: %d\n",
current_task->comm,
current_task->pid,
current_task->tgid,
current_task->state,
current_task->flags,
current_task->policy,
current_task->prio,
current_task->static_prio,
current_task->cpu);
process_count++;
}
pr_info("Number of processes:%u\n", process_count);
return 0;
}
static void test_tasks_exit(void) {
pr_info("%s: In exit\n", __func__);
}
// 需要申明 LICENSE
MODULE_LICENSE("GPL");
// 申明初始化和清理的函数
module_init(test_tasks_init);
module_exit(test_tasks_exit);
然后编写 Makefile:
obj-m += kdebugger.o
all:
make -C /lib/modules/$(shell uname -r)/build -I /lib/modules/$(shell uname -r)/source/include M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
在开始编译之前我们还需要安装最重要的两个依赖:gcc 和内核头文件。
gcc 通常大部分发行版上都有预装,但是一般版本都比较老,较新版本的内核会对 gcc 版本有一定要求,建议先升级到新版本,以 CentOS 为例:
yum install devtoolset-8-gcc
# 然后卸载掉老的 gcc 把新的 gcc 加入到 PATH 中
/opt/rh/devtoolset-8/root/usr/bin/gcc
内核头文件也是必要的,不然我们 include 的那些库编译肯定是过不去的,可以直接通过 yum 安装,但是注意内核头文件一定要和内核版本严格匹配,不像暴露对外的系统调用接口,内核的内部数据结构是经常变化的:
yum install kernel-headers
都顺利的话我们下一步就可以开始编译了,直接当前目录 make 即可,编译完之后我们会发现生成了一个 kdebugger.ko (.ko 文件对标的就是用户态程序编译出来的 .o 文件)文件,这就是我们编译出来的内核模块了。
编译完成之后通过 insmod kdebugger.ko即可将该模块安装到内核,我们可以查看内核模块列表验证一下,赫然出现在了第一列 :
root@dev# cat /proc/modules
kdebugger 16384 0 - Live 0xffffffffc0808000 (O)
xt_statistic 16384 3 - Live 0xffffffffc07fe000
ip6table_mangle 16384 0 - Live 0xffffffffc06b2000
ip6table_filter 16384 0 - Live 0xffffffffc06ad000
nf_tables 204800 0 - Live 0xffffffffc07a7000
nfnetlink_queue 24576 0 - Live 0xffffffffc06f8000
nfnetlink_log 20480 0 - Live 0xffffffffc06ca000
bluetooth 606208 0 - Live 0xffffffffc0712000
ecdh_generic 16384 1 bluetooth, Live 0xffffffffc06f3000
....
内核模块安装时会调用其 init 函数,即我们上面代码中的 test_tasks_init函数,执行我们的 debug 代码,printk会将输出打到内核的 Ring Buffer 中,我们可以通过 dmesg 命令来查看,即可得到我们想要的结果:
root@dev# demesg -TL
....
[Sun Mar 14 18:25:52 2022] test_tasks_exit: In exit
[Sun Mar 14 18:25:52 2022] test_tasks_init: In init
[Sun Mar 14 18:25:52 2022]
Command: systemd PID: 1 TGID: 1 State: 1 Flags: 4194560 Policy: 0 Prio: 120 StaticPrio: 120 Current CPU: 1
[Sun Mar 14 18:25:52 2022]
Command: kthreadd PID: 2 TGID: 2 State: 1 Flags: 2129984 Policy: 0 Prio: 120 StaticPrio: 120 Current CPU: 1
....
[Mon Mar 14 17:30:40 2022] Number of processes:197
最后有个小提示,编写内核模块时一定要谨慎,尽量先在虚拟机中调试,任何微小的疏忽都有可能导致整个操作系统崩溃。
eBPF
eBPF
要让我们的代码跑以 Ring 0 权限跑在内核态中,除了上文提到的内核模块之外,Linux 内核还提供了一种很酷的扩展方案 —— eBPF ()。
eBPF可以理解为内核提供的一个简单的虚拟机,可以让我们提交一些指令到内核运行,虽然 eBPF 有很多限制,会限制指令条数,循环次数不能过多,运行时间、堆栈大小和字节码大小均有要求,另外内核也仅暴露了有限的 API 给 eBPF 指令,但是也基本都够用了,这么严苛的限制反倒可以让我们放开手脚不用担心一不小心让操作系统崩溃,同时相较于直接编写内核模块,eBPF更加的轻量和安全,已经有许多知名的应用是基于 eBPF 技术实现的,比如网络插件 Cilium、安全检测应用 Falco 、可观测性加强应用Pixie等等。
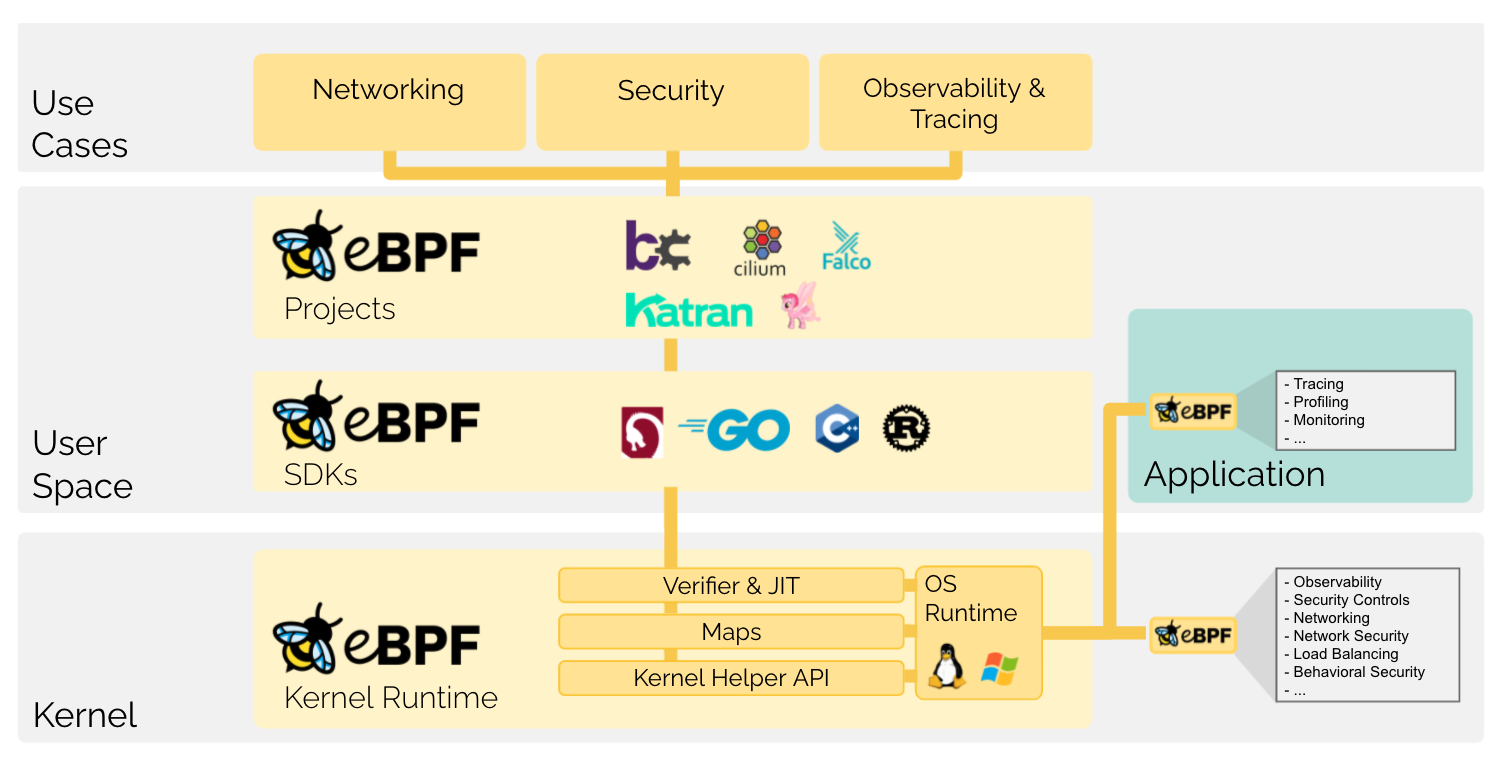
eBPF 程序执行的模型是事件驱动的,说白了就能在内核里面插很多回调函数。
内核提供了很多的 hook 点,我们可以申明 eBPF 程序注册到指定的 hook 点上,当对应的事件发生时就会调用我们的 eBPF 代码执行,目前内核支持的 eBPF 程序类型枚举可以在这里查看 https://elixir.bootlin.com/linux/v5.13/source/include/uapi/linux/bpf.h#L908。
bpftrace
直接编写 eBPF C 代码,然后编译提交给内核执行复杂度和编译内核模块相比也是不相上下,但是我们有更便捷的工具:bpftrace,一个轻量级的 eBPF 程序执行框架,或者说是一门更容易学习和运行的 eBPF 方言。
我们可以直接通过包管理器安装 bpftrace:
# RPM
curl https://repos.baslab.org/rhel/7/bpftools/bpftools.repo --output /etc/yum.repos.d/bpftools.repo
yum install bpftrace bpftrace-tools bpftrace-doc bcc-static bcc-tools
# APT
apt install bpftrace
我们上文中提到的各种各样的 hook 点在 bpftrace 中抽象成了 probe 的概念,当前系统支持的所有 probe 可以通过 -l 参数查看:
root@dev# bpftrace -l
hardware:backend-stalls:
hardware:instructions:
hardware:ref-cycles:
iter:task
iter:task_file
kprobe:FSE_NCountWriteBound
kprobe:FSE_buildCTable_wksp
kprobe:FSE_buildDTable_raw
tracepoint:xhci-hcd:xhci_stop_device
tracepoint:xhci-hcd:xhci_urb_dequeue
tracepoint:xhci-hcd:xhci_urb_enqueue
...
bpftrace 脚本由probe /filter/ { action } 这几部分组成,probe 申明了一个或多个 hook 点,当对应的事件发生时如果满足了 filter 的条件,就会执行 action 里面的逻辑。
完整语法可以参考其官方文档。
Have a try
针对我们这里分析 task_struct 结构的需求,使用 bpftrace 可以非常方便的实现:
# 遍历所有的 task
bpftrace -e 'iter:task { printf("%s:%d\n", ctx->task->comm, ctx->task->pid); }'
不过上面提到的 iter probe 是基于 eBPFTRACING 类别的程序来实现的,至少需要内核版本 5.5,同时需要内核在编译时开启了 BTF 特性,要求相对来说比较高。
内核提供了一种 kprobe 的 eBPF 能力,可以让我们在任意的内核函数之前或者之后插入我们的 eBPF 逻辑。
我们可以在内核中找到我们感兴趣的函数,比如每个进程创建的时候都会调用 kernel_clone 函数(在旧版本内核中为 do_fork,内核内部代码变动频繁,请对照实际使用版本源码分析),然后 kernel_clone 函数会返回一个 pid 来代表该进程(或者线程),那么我们就可以用 kprobe 来实时监测内核中的进程创建:
root@dev# bpftrace -e 'kretprobe:kernel_clone { printf("new process created, pid: %d\n", retval); }'
Attaching 1 probe...
new process created, pid: 21902
new process created, pid: 21903
new process created, pid: 21904
new process created, pid: 21905
...
同时我们看 kernel_clone 的代码会发现它内部还会调用一个 copy_process 的函数,实际执行 task_struct 的复制,且其返回值就是一个 task_struct,那么我们又能观测到这个熟悉的面孔了。
由于这里我们要引用到具体的内核数据结构,因此需要 include 相关的头文件,不能一行写完,所以需要创建一个脚本文件,再传递给 bpftrace 执行:
root@dev# cat copy_process.bt
#include <linux/sched/task.h>
// kretprobe 表示在函数执行后回调, kprobe 是在函数执行之前回调
kretprobe:copy_process
{
$task = ((struct task_struct *) retval);
printf("\nCommand: %s PID: %d TGID: %d State: %ld Flags: %d Policy: %d Prio: %d StaticPrio: %d Current CPU: %d\n",
$task->comm,
$task->pid,
$task->tgid,
$task->state,
$task->flags,
$task->policy,
$task->prio,
$task->static_prio,
$task->cpu);
}
执行脚本之后,我们就可以看到这些字段的输出了:
root@dev# bpftrace process_create.bt
Attaching 1 probe...
Command: crond PID: 22700 TGID: 22700 State: 2048 Flags: 4194368 Policy: 0 Prio: 120 StaticPrio: 120 Current CPU: 0
Command: sh PID: 22701 TGID: 22701 State: 2048 Flags: 4194368 Policy: 0 Prio: 120 StaticPrio: 120 Current CPU: 0
Command: sh PID: 22702 TGID: 22702 State: 2048 Flags: 4194368 Policy: 0 Prio: 120 StaticPrio: 120 Current CPU: 1
...
小结
本文向大家展示了内核模块和 eBPF 这两种比较轻量级的调试小技巧,可以帮助我们更好的了解内核内部的运行时状况,除了本文中举例的进程信息,在分析网络丢包、内核卡死、IO缓存、可疑系统调用等场景下的相关问题也都是非常实用的。