ELF
Executable and Linkable Format,可执行与可链接格式,其一个很熟悉的身份就是 Linux 操作系统的标准可执行文件格式,在 Linux 上运行我们编写的代码时,就需要将其编译成 ELF 格式。
另外它还定义了共享库和核心转储文件的结构和布局。
ELF 文件格式在操作系统中起着重要的作用,它使得我们编写的代码能够被正确地编译、链接和执行。
此外,部分 Unix 系统,如: Solaris、FreeBSD 等也采用 ELF 作为其可执行文件格式。
ELF 文件格式被设计为可扩展和灵活的,以适应不同类型的程序和库。它可以容纳各种类型的数据和指令,包括机器代码、全局和局部符号表、重定位表、调试信息等。这种灵活性使得 ELF 文件格式能够适应不同的编程语言和编译器,并支持各种操作系统特性和功能。
本文将按照 F L E 的顺序分成三个部分介绍 ELF:F: 文件格式 L: 链接流程 E: 运行流程。
F: 文件格式
ELF 是一种通用的标准格式,格式定义的源代码我们可以在 glibc 代码仓库中找到: elf.h。
ELF 文件本质由两部分组成:
- 一些存储着元信息的头部 (下图中红色部分)
- 存储着实际数据的节 (下图中灰色部分)
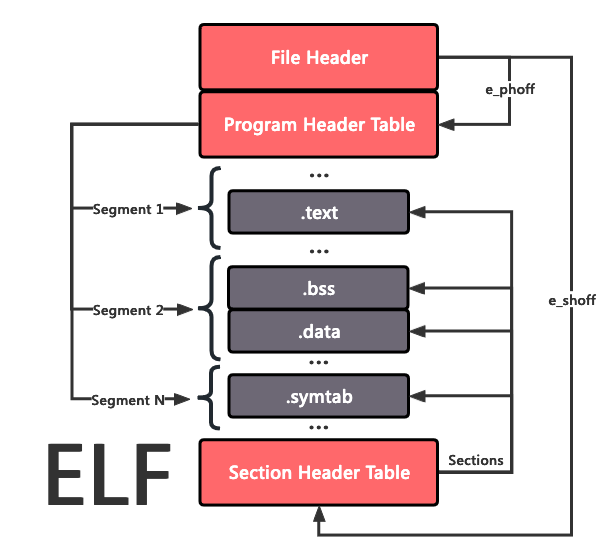
文件头
文件头中定义了一些全局的相关信息。
typedef struct
{
// Magic Number 和一些元信息,共 16 字节,前四字节为 Magic Number,固定为:7f454c46( \177ELF)
// 第四个字节 01 代表 32 位, 02 代表 64 位
// 第五个字节 01 代表小端,02 代表大端
// 剩余的字节当前没有太多含义,一般固定为 01 00 00 00 00 00 00 00 00 00
unsigned char e_ident[EI_NIDENT]; // EI_NIDENT = 16
// 文件类型:
// 1 代表可重定向文件
// 2: 可执行文件
// 3: 共享对象文件
// 4: coredump 文件
Elf64_Half e_type; /* Object file type */
// 文件指令对应的 CPU 架构,我们所熟知的架构有:
// 62: EM_X86_64
// 183: EM_AARCH64
Elf64_Half e_machine; /* Architecture */
// 目标文件版本
Elf64_Word e_version; /* Object file version */
// 程序入口内存地址
Elf64_Addr e_entry; /* Entry point virtual address */
// 段表起始位置
Elf64_Off e_phoff; /* Program header table file offset */
// 节表起始位置
Elf64_Off e_shoff; /* Section header table file offset */
// 处理器特定的一些标志位,一般为 0
Elf64_Word e_flags; /* Processor-specific flags */
//
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
// 段表数量
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
} Elf64_Ehdr;
段: Segment
Segment 是文件在加载并映射到内存的基本单位,内存都是一段一段地映射的。
在 ELF 中,段并没有实体结构,只有段头标注这个段的起始位置和长度,以及一些额外的关于内存映射的元信息,段的内部是一个一个的节,比如:.bss 和 .data 就会被放置在同一个类型为 PT_LOAD 权限为 READ ONLY 的段中。
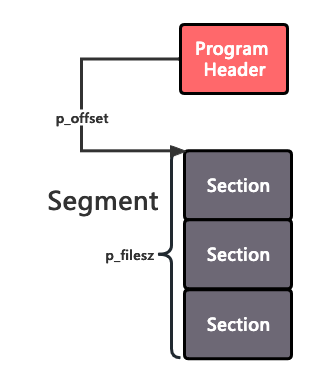
段头: Program Header
typedef struct
{
// 段的类型
// 1 PT_LOAD: 可以加载到内存的段
// 2 PT_DYNAMIC: 动态链接信息段,用于在运行时动态链接
// 3 PT_INTERP: 解释器路径段,用于指定可执行文件依赖的解释器路径
// 4 PT_NOTE: 注释段,存储一些调试或者其他附加信息
// 5 PT_SHLIB: 表示保留给共享库使用的段类型,不常见
// 6 PT_PHDR: 入口段头表,存储了其他段头表的位置
// ...
Elf64_Word p_type; /* Segment type */
// 可读、可写、可执行等权限 flags
Elf64_Word p_flags; /* Segment flags */
// 该 header 描述的段的起始 offset
Elf64_Off p_offset; /* Segment file offset */
// 段被加载后在虚拟内存的起始位置
Elf64_Addr p_vaddr; /* Segment virtual address */
// 段被加载后在物理内存中的起始地址(基本用不到)
Elf64_Addr p_paddr; /* Segment physical address */
// 段在文件中的大小
Elf64_Xword p_filesz; /* Segment size in file */
// 段在内存中的大小,通常 p_memsz 会要大于 p_filesz,比如像 BSS 段在文件中不占用空 间,在运行时却需要分配内存
Elf64_Xword p_memsz; /* Segment size in memory */
// 内存地址对齐方式
Elf64_Xword p_align; /* Segment alignment */
} Elf64_Phdr;
节: Section
ELF 文件中的节(Section)是承载数据的基本单元,每个节都有不同的数据组织方式和承担不同的功能。
在一个 ELF 文件中,各个节存储了不同类型的数据,如代码、数据、符号表、重定位信息、调试信息等。
每个节都有一个唯一的名称和一组属性,用于描述其内容和用途。
节头: Section Header
typedef struct
{
// Section 名称在字符串表中的索引
Elf64_Word sh_name; /* Section name (string tbl index) */
// Section 类别,常见的有:
// 1 SHT_PROGBITS: 代码或者数据
// 2 SHT_SYMTAB: 符号表
// 3 SHT_STRTAB: 字符串表
// 4 SHT_RELA: 可重定向
// 5 SHT_HASH: 符号哈希表
// 6 SHT_DYNAMIC: 包含动态链接所需信息
// 8 SHT_NOBITS: BSS
// ...
Elf64_Word sh_type; /* Section type */
// 一些标志位:
// SHF_WRITE: 可写,允许在运行时修改段的内容
// SHF_ALLOC: 运行期间需要占用内存
// SHF_EXECINSTR: 可运行,包含可执行指令
// SHF_MERGE: 可以被合并,允许相同段中的重复数据进行合并,节省空间
// SHF_STRINGS: 包含字符串,常用于存储字符串表等数据
// SHF_INFO_LINK: 包含其他 Section 的索引或者链接信息,用于描述 Section 之间的关系
// SHF_LINK_ORDER: 具有链接先后顺序
// SHF_COMPRESSED: 段被压缩过,需要解压后才能使用
Elf64_Xword sh_flags; /* Section flags */
// Section 内存起始地址
Elf64_Addr sh_addr; /* Section virtual addr at execution */
// Section 在文件中的 offset
Elf64_Off sh_offset; /* Section file offset */
// Section 大小
Elf64_Xword sh_size; /* Section size in bytes */
// 链接到的其他 Section 的索引
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
// 表中每个条目的大小(如果该 Section 包含一个表的话)
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr; // Section Header
Sections
不同的节在 ELF 文件中按照一定的规则进行组织和排列,一些常见的节包括:。
.bss
BSS (Block Started by Symbol),通常用于存储未初始化的静态变量和全局变量,需要事先分配好空间,待程序运行初始化之后才会被赋值;这段空间在文件中就是空的,只需要申明长度即可,节类型是上文中提到的 SHT_NOBITS。
.comment 注释
该节主要是提供给编译器和其他工具存放注释信息,与程序运行无关,方便 DEBUG 排查问题的,比如 gcc 编译出来的 ELF 文件 .comment 节中就会存放着 gcc 的版本号。
.data .rodata .data.rel.ro 数据节
编译时就能确定值的全局变量、静态变量等会被存储在此,.data 和 .rodata 的区别在于,一个可写的一个是只读的;另外 .data 中的变量会进行内存对齐,在 64 位系统下该节 的 sh_addralign 将会被设置为 8 (字节),以获得最佳的访问效率。
而 .data.rel.ro 和 .rodata 的区别在于,所有带有.rel后缀的节代表其中数据的实际位置在编译阶段无法确定,需要在运行时初始化之后才能赋值,比如 extern、函数指针、字符串指针等变量。
举个例子,比如我们定义了一个字符串指针:
const char *str = "Hello, world!";
那么字符串 "Hello, world!" 会被存储在 .rodata 中,而 str 则是指向这个字符串的指针,但是这个字符串的位置在编译期并不能确定,所以 str 常量会被放置在 .data.rel.ro 节中,等到程序初始化之后, "Hello, world!"的值确定了下来才会被重定向到实际的位置。
.hash 哈希表
.hash 节存储了符号表的哈希表,当符号过多时遍历符号表去找寻对应符号的开销会非常巨大,因此通过 .hash 节存储的符号哈希表能加速符号解析和链接过程。
.text
.text 节是只读的,这一部分存储着程序的可执行的汇编指令,我们所写的代码最终会被编译到这里;处理器在执行程序时,会根据程序计数器(Program Counter)指示的地址从 .text 节中读取指令,然后根据操作码和操作数执行对应的操作。
尽管不同的 CPU 架构指令集会不一样,但 .text节大体的结构是一致的,.text中的代码是以函数为单位进行组织的,每一个函数由函数入口地址所标识,后面则紧跟其对应的汇编指令实现,最后通过 ret 或者 bx lr等指令指示函数结束。
每个程序的函数入口则是在我们上文中提到的文件头中 Elf64_Addr e_entry; 字段指定,操作系统运行程序时就会找到该地址对应的函数,然后开始执行,这个函数又会调用其他函数从而把整个程序串联了起来。
我们可以通过 objdump -d -j .text <elf_file_name>来反编译并查看某个 ELF 文件对应的 .text中的代码内容。
.dynamic
包含了动态链接相关的一些元信息。
该节的基本数据结构是 Elf64_Dyn,组成了一个数组,每个条目有一种类型表明该条目中存储的数据类型,对应的 d_val 或者 d_ptr 则存储了实际的值。
typedef struct {
// 条目类别:
// 0 DT_NULL 标志数组结尾
// 1 DT_NEEDED 该条目 d_un.d_val 标注了所依赖的动态链接库名字符串表索引,会存在多个
// 3 DT_PLTGOT 该条目 d_un.d_ptr 中存储 GOT 表的地址
// 5 DT_STRTAB 该条目 d_un.d_ptr 中存储字符串表地址
// 15 DT_RPATH 动态链接库搜索路径
Elf64_Sxword d_tag; /* entry tag value */
union {
Elf64_Xword d_val;
Elf64_Addr d_ptr;
} d_un;
} Elf64_Dyn;
.line
调试信息的一部分,.line 节中保存了代码文件行号和.text节中指令之间的映射。
.note
.note 跟 .comment 有点类似,但它是有实际作用的,其中会包含 build-id、ABI 版本、操作系统类型等元信息。
.strtab 字符串表
我们通常提到的字符串表其实就是存储在 .strtab 节中,该节中存储了程序函数变量名称、节名称、库名称等等符号字符串。
但是需要注意的是,这里的字符串表和我们代码中字符串常量 & 字面量可没什么关系,代码的字符串只是程序中的一种数据类型,它们会和其他数据类型的常量一起存储在 `.rodata 节区。
字符串表的格式其实非常简单,就是一个一个 null 结尾的 C 字符串紧密的一字排开,或者也可以理解为字符串表的表项是通过 '\0'分隔的,使用的时候,由于字符串不是定长的,因此需要使用字符串在字符串表的字节偏移量来标识该字符串,该偏移量通常使用十六进制而不是十进制的形式存储。
一个示例,某字符串表的内容可能如下:
0053637274312e6f005f5f6162695f7461670063727473747566662e6300646572656769737465725f746d5f636c6f6e657300
按照 '\0'(十六进制为 00)分隔的话,就能解析出如下内容:

| Offset(HEX) | 原始内容 | 解析后 |
|---|---|---|
| 01 | 53637274312e6f | Scrt1.o |
| 09 | 5f5f6162695f746167 | __abi_tag |
| 13 | 63727473747566662e63 | crtstuff.c |
| 1e | 646572656769737465725f746d5f636c6f6e6573 | deregister_tm_clones |
在符号表等其他地方引用时,直接使用 Offset 01 09 13 1e 即可。
.shstrtab 节头字符串表
shstrtab (Section Header STRing TABle) 可以理解为一种存储了所有节名称的特殊字符串表,比如一个 .shstrtab 的内容可能如下:
.symtab\0.strtab\0.shstrtab\0.interp\0.note.gnu.property\0.note.gnu.build-id\0.note.ABI-tag\0.gnu.hash\0.dynsym\0.dynstr\0.gnu.version\0.gnu.version_r\0.rela.dyn\0.rela.plt\0.init\0.plt.got\0.plt.sec\0.text\0.fini\0.rodata\0.eh_frame_hdr\0.eh_frame\0.init_array\0.fini_array\0.dynamic\0.data\0.bss\0.comment
.symtab .dynsym 符号表
.symtab(Static Symbol Table) 和 .dynsym(Dynamic Symbol Table) 结构非常相似,前者是所有符号的全集,而后者只有动态链接相关的符号,包括导出供外部调用和调用外部的 UND 符号,后者是前者的子集,虽然也能通过遍历 .symtab 找到所有的 st_shndx 字段值为 SHN_UNDEF的符号就是动态链接符号,但是出于优化动态链接性能、减少动态链接库内存占用的考虑,ELF 中还是引入了一个额外的 .dynsym 节。
该节中存储了符号表,在符号表中,每一项条目结构如下:
typedef struct
{
// 符号名称在字符串表偏移量
Elf64_Word st_name; /* Symbol name (string tbl index) */
// st_info 是一个长度为 8 位复合字段,高 4 位表示符号类型,低 4 位表示绑定类型;
// 符号类型可能是函数符号、数据对象符号和未定义符号等;
// 绑定则可能是全局绑定或者是局部绑定,全局绑定则意味则该符号在程序全局可见,局部绑定
// 的符号则仅在其定义的模块内部可见,比如局部变量、私有函数等
unsigned char st_info; /* Symbol type and binding */
// 符号的其他属性,如符号的可见性等
unsigned char st_other; /* Symbol visibility */
// 符号所在节区的索引
// SHN_UNDEF 0 代表该符号为动态链接
Elf64_Section st_shndx; /* Section index */
// 符号在其节中对应的偏移
Elf64_Addr st_value; /* Symbol value */
// 大小
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;
符号表主要的作用是用于在链接阶段,供链接器查询某个符号对应的值地址,从而找到对应的实现代码。
由于代码段中是通过地址来标识变量的,所以当我们需要在运行时知道某个变量对应的名称,符号表也是必不可少的,这对于调试很有帮助,但是当不需要线上调试的时候,我们通常会选择在最终可执行文件中移除该部分以减少体积。
.got .plt
GOT (Global Offset Table) 全局偏移表,是用于确定动态链接函数实际位置的一张表,在编译阶段是留空的,程序启动的时候才会逐渐填充。
PLT (Procedure Linkage Table) 程序链接表,这是实现 Lazy Binding 的关键,动态链接定义的函数被调用时,会先跳转到 PLT 表,然后 PLT 会调用 GOT 查询这个函数实际的定义位置,如果 GOT 中没有该函数的条目,PLT 就会调用链接器去解析该函数的地址,然后写入到 GOT 中,再跳转到函数定义位置执行代码。
L: 链接流程
当我们在引用第三方库时,需要将库文件链接到我们的程序中,以便在运行时能够找到对应的代码入口和函数实现。
链接分为静态链接和动态链接两种,静态链接会将库文件并入到最终的 ELF 二进制中,而动态链接则是在运行时再去动态查找库文件。
选择静态链接还是动态链接取决于具体的应用需求和目标平台。静态链接适用于需要独立部署、可移植性要求高的场景,而动态链接适用于共享库的复用和更新的场景。在实际开发中,可以根据项目需求和性能、资源等方面的考虑,选择合适的链接方式来引用和管理第三方库。
静态链接
静态链接通常是编译流程的最后一环,大体流程如下:
文件载入
第一步需要将 ELF 目标文件和所有要链接的 ELF 库文件载入,读取其中相关的节。
重定向
链接器会遍历所有文件的符号表,对于所有未定义的符号,在其他文件的符号表中查找对应的实现(如果在多个文件中都有定义通常会选择第一个),保存找到的符号定义,供之后使用,如果无法找到就会报:symbol not found, 终结当前编译流程。
在所有符号全部遍历后,会需要将所有未定义的符号更新为实际符号定义的地址值,即更新将对应的 Elf64_Sym 结构体中的 st_value 字段,这一步通常被称为重定向。
段合并
最后,由于要最终输出一个 ELF 文件,因此需要将这些文件中的 .text .data .bss等节合并成一个,默认情况下链接器会丢弃静态链接库中未被使用的符号,不过我们也可以通过编译参数 --whole-archive 来要求链接器合并所有符号到最终文件中。
动态链接
动态链接的流程相较于静态链接则更为简单:
文件载入
第一步还是和静态链接一样,当一个程序尝试启动的时候,会调用链接器找出所有的动态链接库,并将其加载到内存中,动态链接库是在进程之间共享的,因此如果其他的进程已经加载过了这个库,那么新的进程只需要 mmap映射过去即可。
重定向
所有动态链接库加载完成之后,和静态链接一样,需要将符号重定向,但是动态链接并不会直接修改符号表,符号表在运行阶段就是只读的了,而是会修改 GOT (Global Offset Table) 表,将实际定义地址写入。
所有未定义符号全部重定向完成之后,程序就可以正常运行了。不过如果在这期间有符号无法找到定义,则程序会立刻退出并报错:symbol not found。
E: 运行流程
在上面的段落中,我们详细了解了 ELF 文件的格式,各个组成部分的含义,这是它们处于文件时静态状态,当 ELF 文件被执行的时候,各个部分之间又是如何串联并运行起来的呢?
在 Linux 系统下,ELF 加载并运行的入口是 load_elf_binary 函数,大概分为如下流程。
除了直接阅读内核源代码,我们还可以使用 bpftrace 辅助我们进行分析,详细使用教程可以参考《Linux 内核轻量级调试小技巧》,比如这里 load_elf_binary 函数签名为:
static int load_elf_binary(struct linux_binprm *bprm);
入参是一个 linux_binprm结构体,当我们通过包管理命令安装好了 bpftrace 之后,执行如下命令(这里为了方便演示牺牲可读性压缩成了单行命令,实际运行时可以使用脚本文件的形式)就可直接打印出来内核中 load_elf_binary 函数每次被调用时,对应的 bprm 参数中的各个变量值究竟都是什么:
bpftrace -e 'kprobe:load_elf_binary { $bprm = (struct linux_binprm*)arg0; printf("load_elf_binary called with bprm:\n"); printf(" filename: %s\n", str($bprm->filename)); printf(" interp: %s\n", str($bprm->interp)); printf(" execfd: %d\n", $bprm->execfd); printf(" argc: %d\n", $bprm->argc); printf(" envc: %d\n", $bprm->envc); printf(" e_uid: %d\n", $bprm->cred->euid.val); printf(" e_gid: %d\n", $bprm->cred->egid.val); }'
任意执行一个二进制程序触发 load_elf_binary 后会有如下输出:
load_elf_binary called with bprm:
filename: ./helloworld
interp: ./helloworld
execfd: 0
argc: 1
envc: 37
e_uid: 0
e_gid: 0
该函数出参为一个 int,可以这么分析:
#bpftrace -e 'kretprobe:load_elf_binary { printf("load_elf_binary called with ret: %d\n", retval); }'
Attaching 1 probe...
load_elf_binary called with ret: 0
load_elf_binary called with ret: 0
load_elf_binary called with ret: 0
load_elf_binary called with ret: 0
load_elf_binary called with ret: 0
load_elf_binary called with ret: 0
load_elf_binary called with ret: 0
基本校验
这一步会对 ELF 的文件头信息进行一些基本的校验,比如:
- Magic number
e_type是否为可执行类型 (ET_EXECorET_DYN)- 架构是否和当前 CPU 架构匹配
加载段表
内核会根据 ELF Header 中的 e_phoff 找到段表的起始位置,然后根据 e_phnum知道段的数量一次性从文件中将所有的 section header 全部 read出来。
如果段表中存在类型 PT_INTERP 的解释器段,则内核还会在该段中指定的解释器位置进行加载,通常是:/lib/ld-linux.so.2,解释器会在之后负责加载并解析程序运行中会用到的动态链接库。
内存加载
接下来内核会遍历所有的类型为 PT_LOAD 的可加载段,根据段头中的内存起始位置和内存大小分配对应的内存,同时设置读写权限。
理论上这些变量和函数的位置都是固定的,因为这些都是在 ELF 文件中固定存在的,但是实际我们去运行程序的时候,就会发现似乎并实际上不是这样。这是 ASLR (Address Space Layout Randomization) 机制作用的结果,为了避免内存溢出等攻击,该机制会让虚拟内存地址随机化,从而避免攻击者能提前得到某个敏感变量的内存地址而展开攻击。
在内存加载的时候,所有的可加载段中的变量都需要加上偏移量 load_bias,才是它们实际的内存地址。
分配完内存后,内核就会将所有的段中的数据复制到对应的内存地址,比如我们所熟知的 .text .data 段就会位于这些可加载段中,这些段内的变量经过这一步之后就正式完成了初始化。
设置变量
在 create_elf_tables函数中,内核会将传入的命令行参数和环境变量等通过 PUT_USER压入进程栈中,供进程执行时读取。
启动
一切准备就绪后,内核会将控制权移交给 Header 中指定的程序入口点,在大部分编译器的实现中,这个函数通常不会直接是用户代码中的main函数,程序运行时本身在启动之前也会有一些初始化工作需要完成,例如在 gcc 和 g++ 编译出的程序中这个入口是 _start函数,在 Golang 标准编译器中,这个入口是_rt0_amd64_linux 。
到此 ELF 加载阶段就全部完成,用户进程正式开始启动。
References
- ELF File Formats Manual https://man7.org/linux/man-pages/man5/elf.5.html
- Executable and Linking Format (ELF) Specification https://refspecs.linuxbase.org/elf/elf.pdf
- ld - The GNU linker https://linux.die.net/man/1/ld