函数链接
根据函数在编译期间的链接方式, 我们可以将函数分为三种:

- 直接调用(Direct Call):这是最直接的一种方式,函数地址在编译时就已经确定,调用时直接跳转到目标地址。
- 静态链接(Static Linking):在编译时将库与程序合并,尽管在单个编译单元内不确定函数的具体地址,但在链接阶段会解析所有符号,最终生成的可执行文件包含所有必要的代码,无需依赖外部库。
- 动态链接(Dynamic Linking):函数的地址在编译期间不可知,程序启动后才能通过加载动态库获取到实际的函数代码地址。
前两种实现方式相对简单直接,本文主要分析第三种——动态链接是如何实现的。
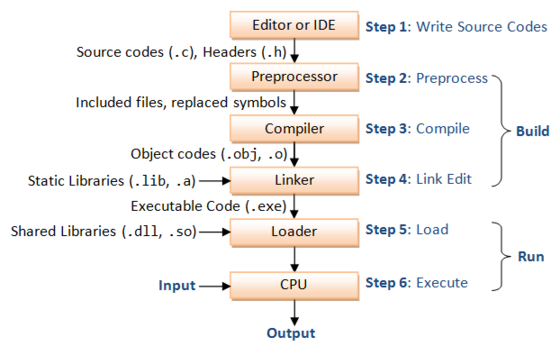
另外在开始之前,可以再简单复习一下编译链接流程:
动态链接的 Hello World
首先让我们从一个最简单的动态链接模型开始,先创建一个提供 say_hello()的动态链接库:
// file: hello.h
void say_hello();
// file: hello.c
#include "hello.h"
#include <stdio.h>
void say_hello() {
printf("Hello, World!");
}
然后将之编译成一个动态链接库libhello.so:
# -fPIC 代表生成位置无关代码,即使用相对地址而不是绝对地址
gcc -o libhello.so -shared -fPIC hello.c
然后我们再提供一个程序执行入口来调用这个动态链接库:
// file: main.c
#include "hello/hello.h"
int main() {
say_hello();
return 0;
}
编译这个文件并链接上上面生成的动态链接库:
gcc main.c -I. -L./hello -lhello -o main
运行这个程序,不过在这之前我们还需要配置一下让链接器可以找到我们生成的动态链接库:
export LD_LIBRARY_PATH=$(pwd)/hello:$LD_LIBRARY_PATH
运行它:
root# ./main
Hello, World!
一个再简单不过的程序,朴实无华的流程,但 main程序在调用say_hello()这个函数时,底层又是怎么实现的呢,这背后又隐藏着哪些秘密呢?
常规函数调用
首先让我们回顾一下常规的函数调用是如何实现的,在调用非动态链接的函数时,ELF 文件中调用该函数行对应的汇编代码大致如下:
116e: e8 d6 ff ff ff call 1149 <say_hello>
0x1149 (当然代码段被加载到内存之后需要加上 ASLR 随机生成的基址地址)该内存位置将存放着 say_hello()这个函数所有编译出的指令,调用 call 指令之后程序计数器寄将(PC)指向 0x1149,从该位置开始执行 say_hello() 函数的指令, 从代码的视角来看就是这个函数开始执行了。
这是非动态链接的流程,要调用的函数在编译链接期间就已经确认好了最终的内存位置,只需要在调用的位置插入该函数的内存地址即可。
但动态链接的函数,在链接期间肯定是确认不了内存位置的, 这又该如何处置呢?
动态链接函数调用
接下来的调用链路会比较复杂,我们使用 gdb来进行汇编指令查看及内存分析。
首先我们需要将二进制添加一些额外的参数进行编译避免编译器优化带来的困惑以及生成 debug 符号(比如汇编指令到源代码文件及行号的映射):gcc main.c -g -O0 -I. -L./hello -lhello -o main。
然后我们在 gdb中打开该二进制文件:gdb --args ./main。
下面就可以在 gdb界面中对程序进行分析了,在我们输入 run命令之前,程序是尚未启动的,我们先观察一下此时的状态。
首先我们先查看一下 main()函数的汇编代码,看一下 say_hello()这个函数是如何被调用的,和静态链接的指令又有何不同,使用 disassemble子命令可以方便的查看某一个函数的汇编指令:
(gdb) disassemble main
Dump of assembler code for function main:
0x00000000004005fd <+0>: push %rbp
0x00000000004005fe <+1>: mov %rsp,%rbp
0x0000000000400601 <+4>: mov $0x0,%eax
0x0000000000400606 <+9>: call 0x400500 <say_hello@plt>
0x000000000040060b <+14>: pop %rbp
0x000000000040060c <+15>: ret
End of assembler dump.
(gdb)
可以看到调用 say_hello()函数的中一行仍然是调用了 CALL 指令,但是 CALL 指令的操作数变成了一个特殊的函数:say_hello@plt。
我们继续查看这个特殊函数的汇编指令:
(gdb) disassemble 'say_hello@plt'
Dump of assembler code for function say_hello@plt:
0x0000000000400500 <+0>: jmp *0x200b22(%rip) # 0x601028 <say_hello@got.plt>
0x0000000000400506 <+6>: push $0x2
0x000000000040050b <+11>: jmp 0x4004d0
End of assembler dump.
(gdb)
%rip是指令指针寄存器(Instruction Pointer Register),存储当前指令的地址,这里 0x200b22(%rip)代表当前地址往后数 0x200b22个字节 的位置,0x400500 + 0x200b22 = 0x601022 对齐到 8 字节则为 0x601028;同时使用 * 取指针引用,然后 jmp指令跳转到 0x601028指向的地址。
既然0x601028是个指针,那么我们就再看看这个指针里面存的是什么东西,使用 x(eXamine)来查看指针内容:
(gdb) x/gx 0x601028
0x601028 <say_hello@got.plt>: 0x0000000000400506
可以看到这里又指向回了 say_hello@plt函数的第二行:
0x0000000000400506 <+6>: push $0x2
为何绕了一圈又回来了呢,这里我们先按下不表,继续往下走,下一行又是一个 jmp指令,跳转到了地址 0x4004d0:
0x000000000040050b <+11>: jmp 0x4004d0
jump 到了这个地址说明这里仍然是指令,我们使用 disassemble继续查看:
(gdb) disassemble 0x4004d0,+16
Dump of assembler code from 0x4004d0 to 0x4004e0:
0x00000000004004d0: push 0x200b32(%rip) # 0x601008
0x00000000004004d6: jmp *0x200b34(%rip) # 0x601010
0x00000000004004dc: nopl 0x0(%rax)
End of assembler dump.
(gdb)
可以看到这里将 0x601008 地址入栈之后,又跳转到了0x601010指针所指向的地址。
但当我们想要查看这两个地址的内容时,会很遗憾的发现此时都是空的:
(gdb) x/gx 0x601008
0x601008: 0x0000000000000000
(gdb) x/gx 0x601010
0x601010: 0x0000000000000000
(gdb)
难道线索到这里就中断了吗?程序运行起来是没有问题的,说明在运行的时候流程是不会在这里中断的,那我们也将程序运行起来之后再观察一下,使用 start命令让程序启动并暂停之后我们再查看一下:
(gdb) start
Temporary breakpoint 1 at 0x400601: file main.c, line 4.
Starting program: ./main
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Temporary breakpoint 1, main () at main.c:4
4 say_hello();
(gdb) x/gx 0x601008
0x601008: 0x00007ffff7ffe2e0
(gdb) x/gx 0x601010
0x601010: 0x00007ffff7fd8d30
(gdb)
这两个指针在加载完成之后就被填充了实际的内存地址。
第一个指针是 push的参数,所以它是一个具体的变量值,而第二个是jmp的参数所以这里是指令,应该是某个函数的入口:
(gdb) x/gx 0x00007f34947f3150
0x7f34947f3150: 0x0000000000000000
(gdb) info symbol 0x00007f34945e6a30
_dl_runtime_resolve_xsavec in section .text of /lib64/ld-linux-x86-64.so.2
(gdb)
进一步分析,第一个指针是干啥的 这里我们不得而知,而 第二个指针对应的是_dl_runtime_resolve_xsavec函数入口。进一步分析_dl_runtime_resolve_xsavec函数的实现细节我们会发现其相当复杂,这里我们先暂且打住,回归理论分析。
实现思路
首先抛开上面的细节不谈,从 CPU 的角度来说,调用函数本质上不就是跳转到一个新的内存地址继续执行指令么?
所以最关键的就是这个内存地址如何获取。
静态链接的时候函数地址是能在链接期就确定的,但是我们动态链接函数的地址在动态链接库加载之后就也能知道了,那这样,我们编译的时候先留一个占位符,然后启动后加载了函数之后再更新一下汇编指令,将函数地址写回到调用的地方:
call [--PlaceHolder--] -> call 0003ld
这样后续运行不就和静态链接一样了?
很遗憾,这个方案的问题在于,需要修改程序指令所在的代码段(.text)内存。
而操作系统出于节省内存资源,提高重复加载效率的考虑,会将代码段、只读数据段(.rodata)在进程间复用,即我们运行同一个二进制启动了多个进程,它里面的代码指令也只会占用一份内存空间;
那么代码段就只能是只读的,不然每个进程加载的动态链接库顺序或者数量可能不一致,所以加载出来的函数内存地址也不一样,这样就乱套了;另外操作系统不允许自修改代码也有安全方面的考虑,避免代码注入等攻击方式。
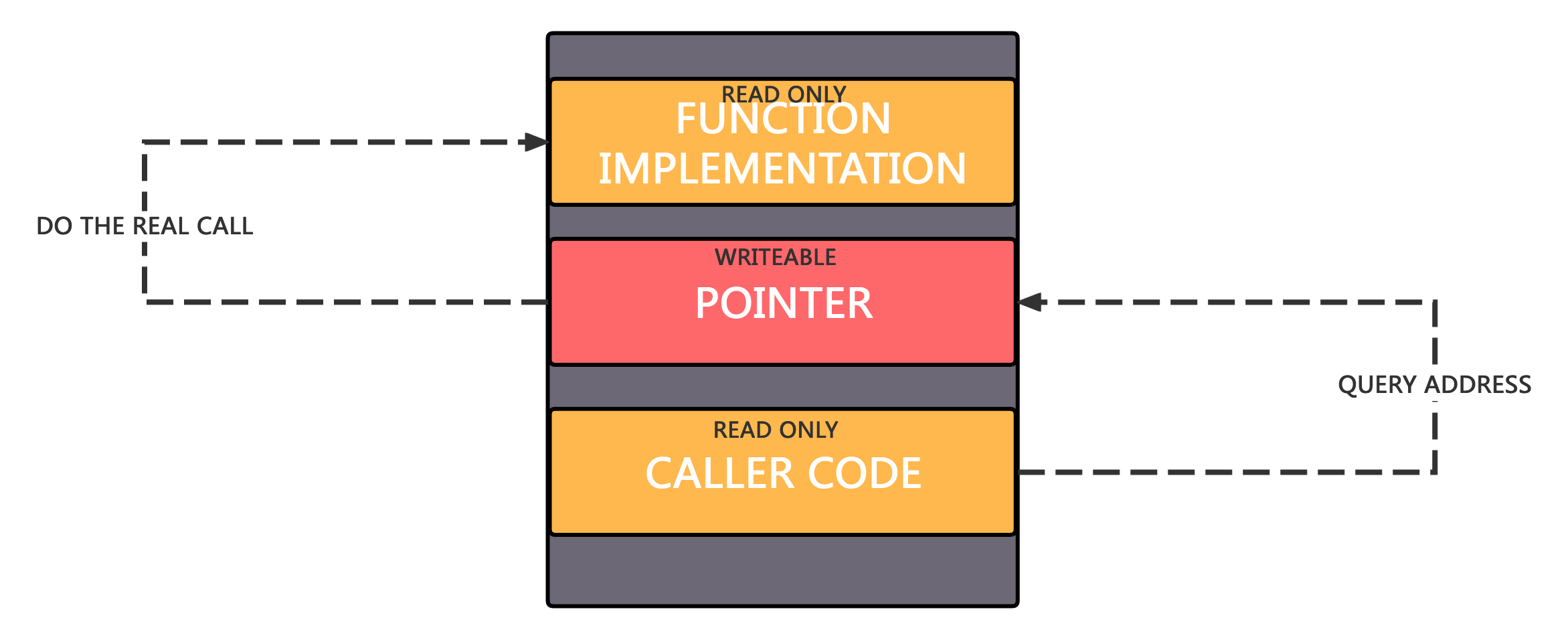
既然代码段是只读的,那么我们折中一下,去可以修改的数据段(.data)找一个位置,存放加载后的函数地址,每次我们执行函数的时候就先去这个数据段里面把实际地址读取出来,然后再跳转过去执行,这样不就完美了么?
是的,这就是动态链接函数调用大概的实现思路。
实现原理
BLACK SHEEP WALL.
接下来让我们切换到上帝视角,再来过一遍动态链接的实现原理。
PLT 与 GOT
GOT(Global Offset Table)全局偏移表,可以理解为一个指针数组,这里面的每一个条目都跟一个对应的动态链接函数对应,在程序加载完成之后, 这个指针就会指向实际的函数地址; 也就是我们上一节指的,位于可写的数据段中用来存放实际地址的地方。
PLT(Procedure Linkage Table)过程链接表,这个表中的每一项都是一个特殊的函数, 所有调用动态链接函数的指令, 都会先调用到这一个特殊的函数, 这个函数位于不可修改的代码段, 会配合 GOT 完成实际的动态链接调用流程。
其实,这两张表也并不是什么特殊的黑科技, 顺着我们上面的思路, 实现动态链接,确实得有这么两个地方去放一些东西,实现之后也总得起个名吧,就有了 GOT 与 PLT。
实际调用流程
我们再从理论上分析一下我们文章开头的那个对于 say_hello() 函数动态链接调用的那个 demo:
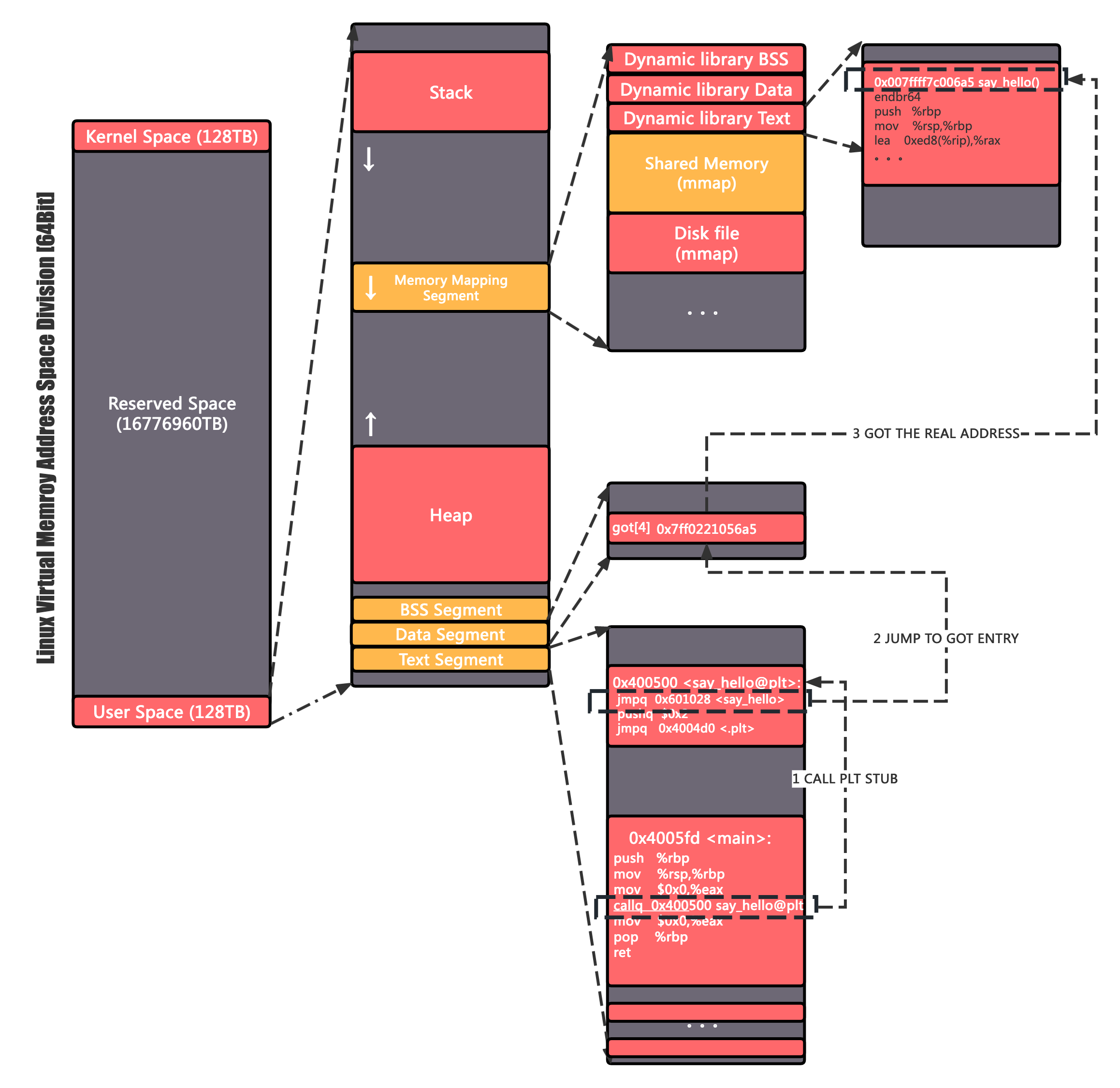
- 首先编译器会在所有调用动态链接函数的地方,跳转到
PLT表,即 demo 中我们反汇编指令看到的特殊函数say_hello@plt PLT函数第一行就会直接跳转到GOT表中指针(0x601028=GOT表第五项)指向的位置- 但是第一次调用的时候, 动态链接库还没有加载,所以
GOT表中的指针一开始会指向了PLT函数的第二行,加载这个动态链接库 PLT函数第二行会将立即数 2 入栈(push $0x2),主要是表明这是PLT的第二个元素,后续让链接器可以根据栈里的数字知道要解析哪个函数,然后跳转到PLT表的第一项(4004d0)PLT表第一项也是一个特殊的函数- 会将
GOT表第二项入栈(push 0x200b32(%rip) # 0x601008),这里保存了当前模块的 ID,解析逻辑内部会用到 - 然后跳转到第三项执行指令(
jmp *0x200b34(%rip) # 0x601010) PLT表第三项在程序启动后会指向_dl_runtime_resolve_xsavec函数,会将实际函数的地址解析之后再写入到GOT中对应的条目(GOT[4]= 0xXXXXXc)
- 会将
- 加载完成之后,会直接再继续跳转的实际函数地址执行指令,完成此次调用
- 后续调用的时候,
say_hello@plt直接跳转到GOT[4]就能直接执行了
函数加载解析完成之后,从整个内存的宏观角度来看整体调用链路图如下:
[注解]:
- 首先 Linux 内存被分为了用户态空间和内核态空间以及巨大的保留地,这里我们所有的故事都是发生在的低地址用户态内存空间内的
- 用户态内存空间由低到高依次是:代码段、数据段(已初始化
.data)、数据段(未初始化.bss)、堆、内存映射区、栈 - 当前程序的代码顾名思义会在只读的代码段(
.text) GOT表位于数据段(已初始化)部分(.data)- 动态链接库都会被加载到内存映射区(从磁盘文件直接映射到内存),它前面会给堆预留足够充足的扩容空间,所以这个地址的起始位置会非常高,也就是我们看到的实际动态链接库函数代码所在地址数字会非常大
- 动态链接库也有自身的
.text.data.bss
这就是整体的调用实现流程(HOW),不过在这期间关于为什么(WHY)这么实现细心的你肯定会有一个很大的疑问:
为什么有了 GOT 还需要 PLT?
理论上,GOT里面保存着实际的函数地址,这个信息是必须的,而PLT似乎则可有可无。
是的,其实上面这个猜想并没有问题,gcc 6.1 版本引入了 -fno-plt选项( 合入 pr 细节),允许编译时添加该选项以禁用PLT转为直接通过GOT调用,从而获取一定的性能提升。
(plt enabled)
call 400500 <say_hello@plt>
=>
(plt disabled) call the address in got directly
call *0x2eac(%rip) # 3fe8 <say_hello@Base>
但是这也是有代价的,禁用 PLT之后,动态链接库就无法lazy binding了,没有PLT辅助函数第二行和第三行的存在,动态链接函数就无法在运行时再进行解析,就算GOT初始化为链接器的地址,没有第二行立即数的入栈也无从得知是要解析哪一个函数。
Dump of assembler code for function say_hello@plt:
0x0000000000400500 <+0>: jmp *0x200b22(%rip) # 0x601028 <say_hello@got.plt>
0x0000000000400506 <+6>: push $0x2
0x000000000040050b <+11>: jmp 0x4004d0
Lazy Binding懒加载是一个非常有用的特性, 懒加载启用之后,所有的符号,只会在用到的时候才被解析, 能大幅提升程序启动速度, 降低不必要的内存消耗, 同时也也有助于一些诸如热加载之类的黑科技实现。
所以除了一些特殊的场景,大部分时候,动态链接的实现还是需要仰仗PLT和GOT的通力合作。